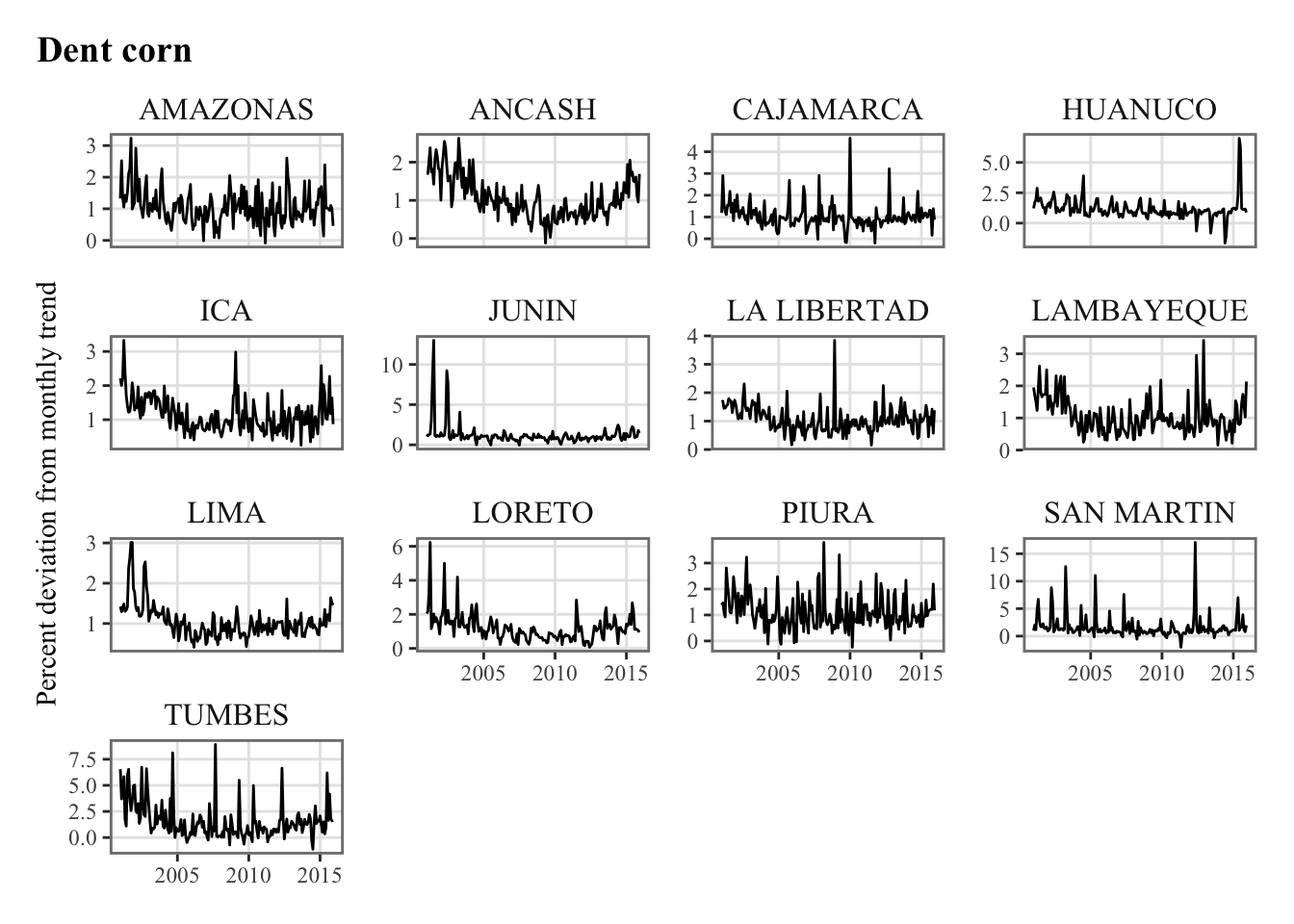
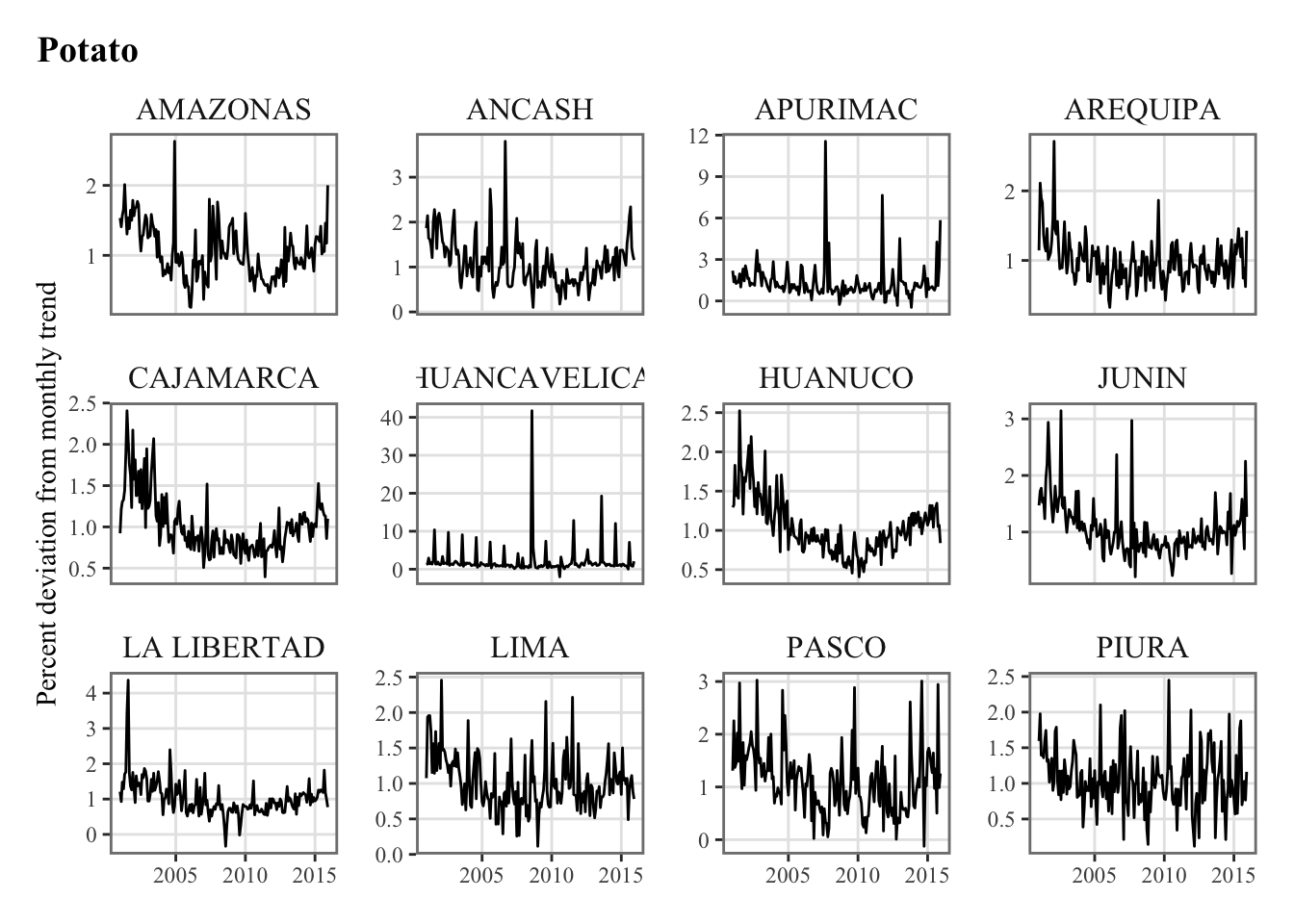
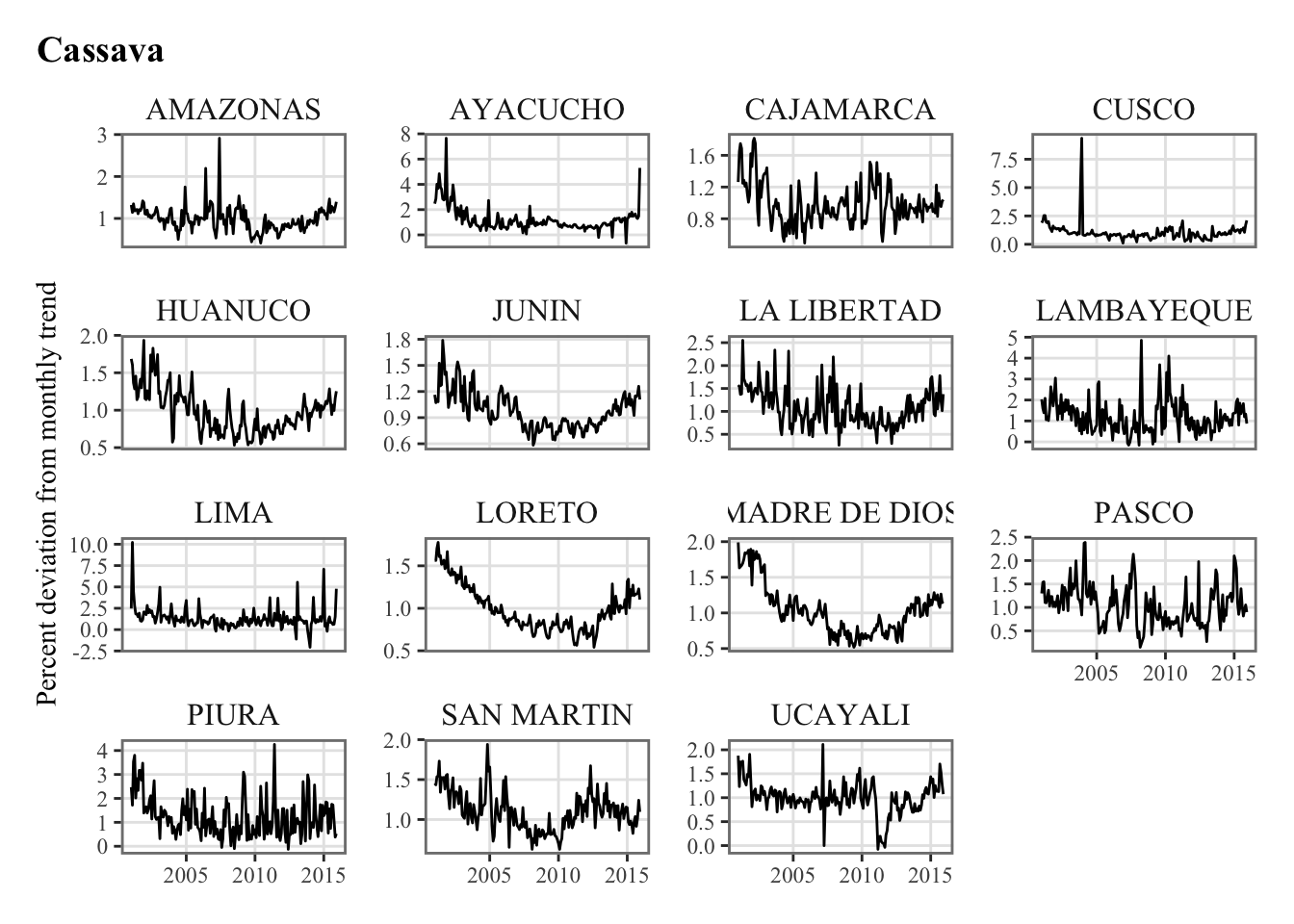
y_new |
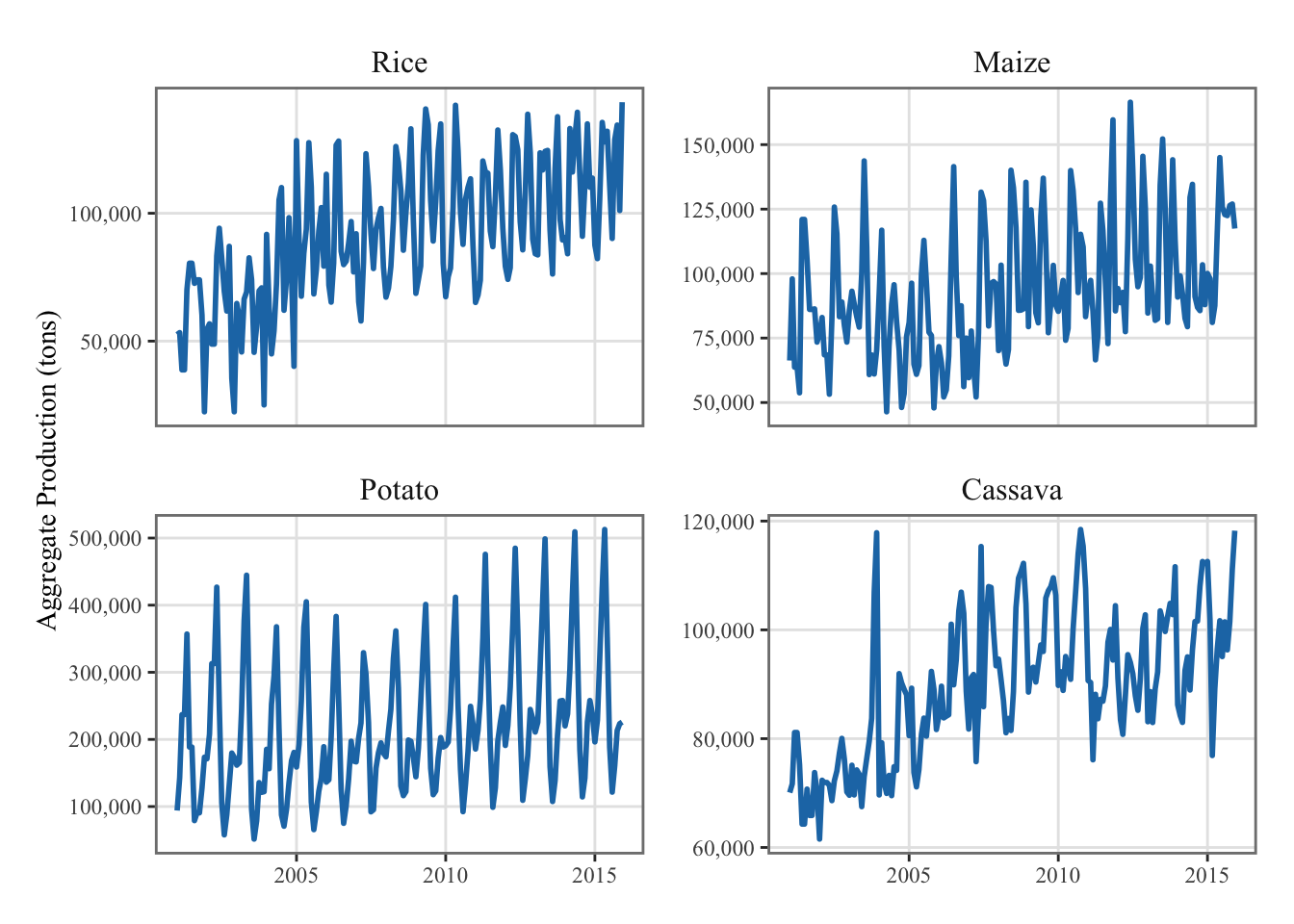
Monthly Agricultural Production (tons) |
|
y |
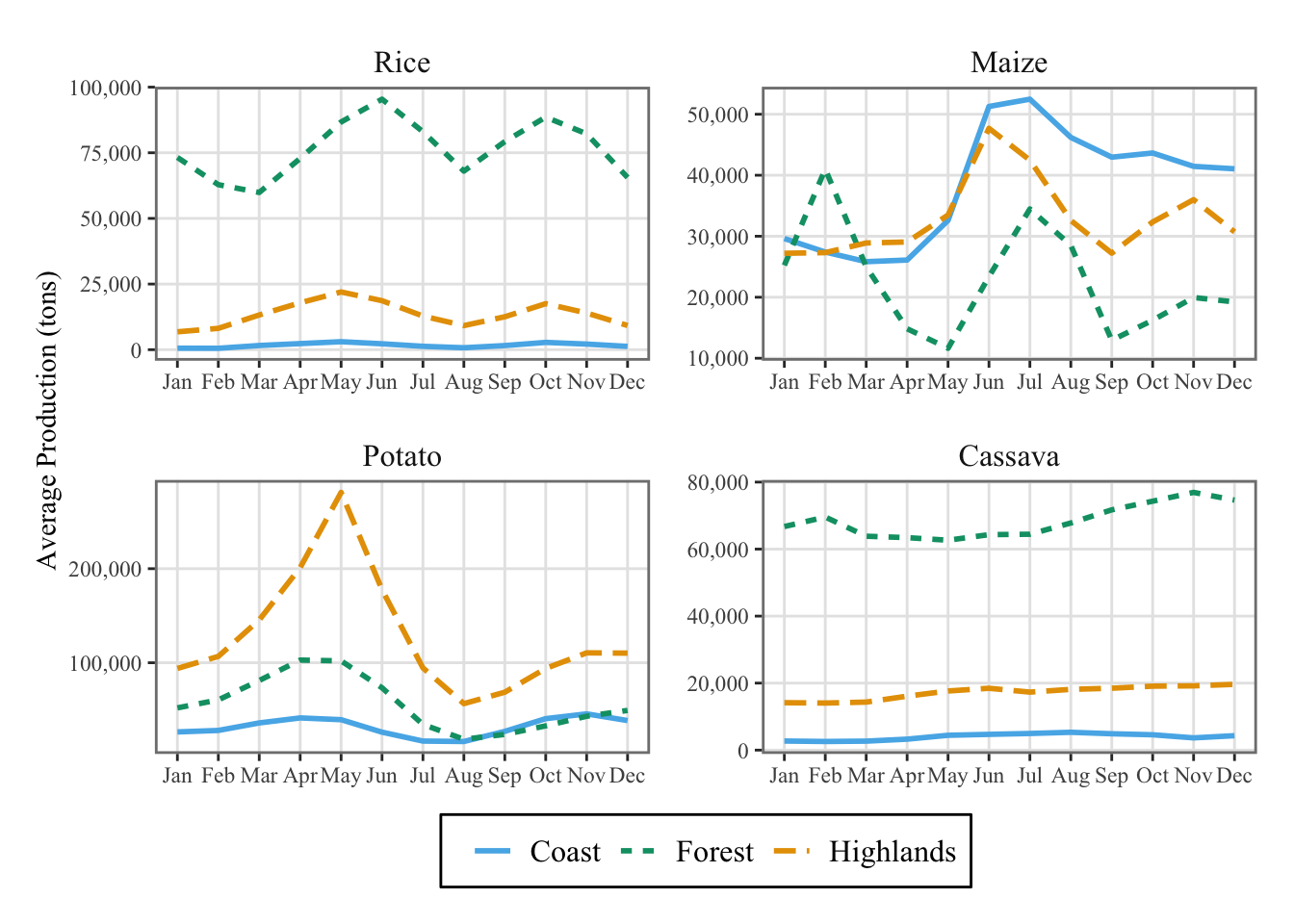
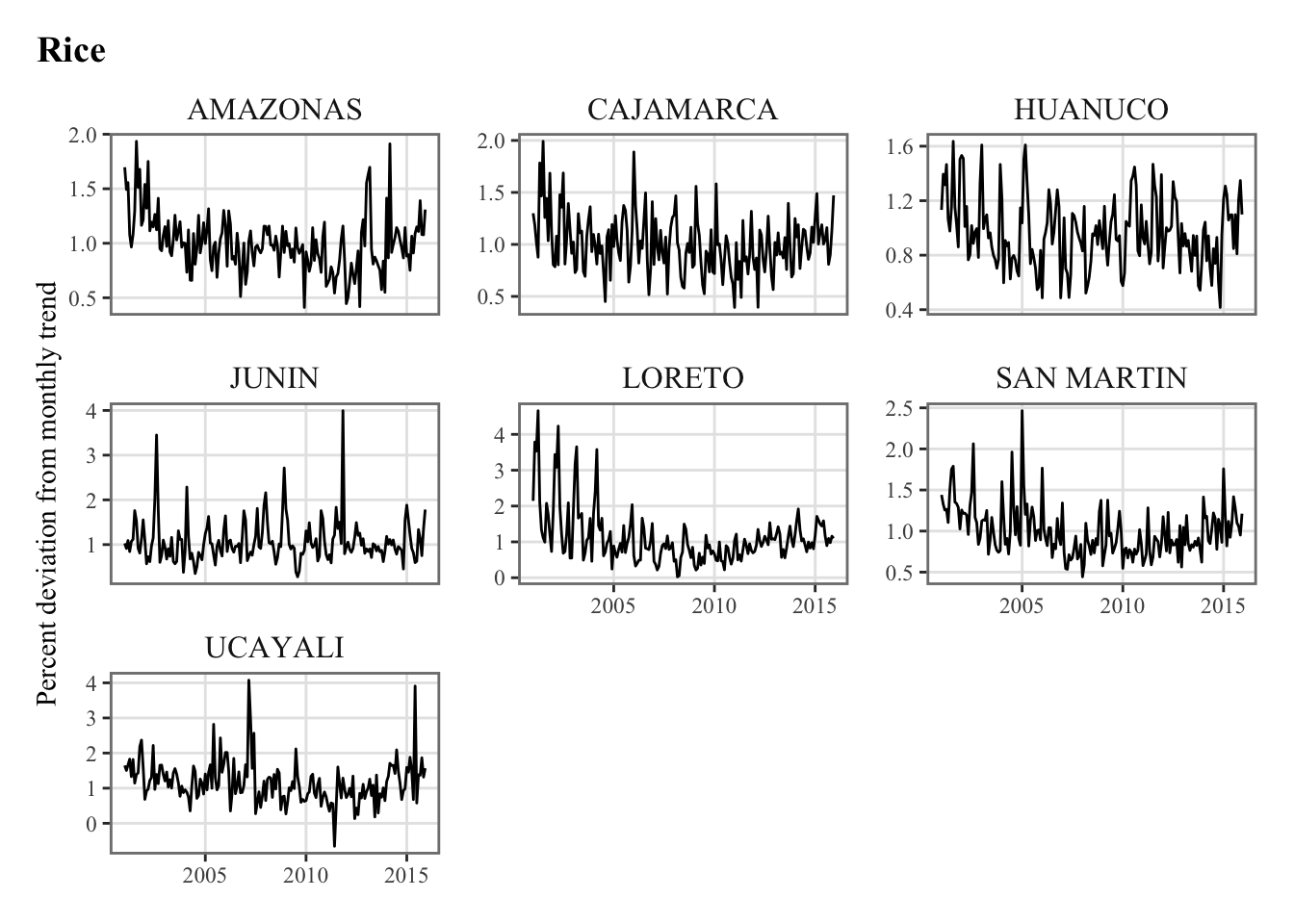
Monthly Agricultural Production (pct. deviation from monthly trend) |
|
product |
character |
Name of the crop (in Spanish) |
product_eng |
character |
Name of the Product (in English) |
region_id |
integer |
Region numerical ID |
region |
character |
Name of the region |
year |
numeric |
Year (YYYY) |
month |
numeric |
Month (MM) |
date |
Date |
Date (YYYY-MM-DD) |
ln_prices |
numeric |
Product price (log) |
ln_produc |
numeric |
Production (log of tons) |
Value_prod |
numeric |
Production (tons) |
surf_m |
numeric |
Planted Surface during the current month (hectares) |
Value_surfR |
numeric |
Harvested Surface (hectares) |
Value_prices |
numeric |
Unit Price (Pesos) |
campaign |
numeric |
ID of the planting campaing (starting in August) |
campaign_plain |
character |
Years of the planting campaing (starting in August) |
month_campaign |
numeric |
Month of the planting campaing (August = 1) |
surf_lag_calend |
numeric |
Planted Surface laggued by the growth duration computed from the caledars (hectares) |
perc_product |
numeric |
Share of the annual production harvested at month m |
perc_product_mean |
numeric |
Average share of the annual production harvested at month m |
diff_plant_harv |
numeric |
Difference between planted and harvested surfaces during month m |
exposition |
numeric |
Cumulative difference between planted and harvested surfaces |
exposition_trend |
numeric |
Trend of the exposition using HP filter |
exposition_detrended |
numeric |
Difference between the exposition and its trend |
exposition_norm |
numeric |
Normalisation of the detrended exposition |
temp_min |
numeric |
Monthly average of daily min temperature |
temp_max |
numeric |
Monthly average of daily max temperature |
temp_mean |
numeric |
Monthly average of daily mean temperature |
precip_sum |
numeric |
Monthly sum of daily rainfall |
perc_gamma_precip |
numeric |
Percentile of the monthly precipitation (Estimated Gamma Distribution) |
temp_min_dev |
numeric |
Deviation of monthly min temperatures (temp_min) from climate normals (1986 – 2015) |
temp_max_dev |
numeric |
Deviation of monthly max temperatures (temp_max) from climate normals (1986 – 2015) |
temp_mean_dev |
numeric |
Deviation of monthly mean temperatures (temp_mean) from climate normals (1986 – 2015) |
precip_sum_dev |
numeric |
Deviation of monthly total rainfall (precip_sum) from climate normals (1986 – 2015) |
spi_1 |
numeric |
SPI Drought Index, Scale = 1 |
spi_3 |
numeric |
SPI Drought Index, Scale = 3 |
spi_6 |
numeric |
SPI Drought Index, Scale = 6 |
spi_12 |
numeric |
SPI Drought Index, Scale = 12 |
spei_1 |
numeric |
SPEI Drought Index, Scale = 1 |
spei_3 |
numeric |
SPEI Drought Index, Scale = 3 |
spei_6 |
numeric |
SPEI Drought Index, Scale = 6 |
spei_12 |
numeric |
SPEI Drought Index, Scale = 12 |
ONI |
numeric |
Oceanic Niño Index |
elnino |
numeric |
1 if El-Niño event, 0 otherwise |
lanina |
numeric |
1 if La-Niña event, 0 otherwise |
State |
numeric |
State: "La Niña", "Normal", or "El Niño" |
enso_start |
numeric |
1 if current date corresponds to the begining of one of the three states, 0 otherwise |
enso_end |
numeric |
1 if current date corresponds to the end of one of the three states, 0 otherwise |
temp_min_dev_ENSO |
numeric |
Deviation of Min. Temperature from ENSO Normals |
temp_max_dev_ENSO |
numeric |
Deviation of Max. Temperature from ENSO Normals |
temp_mean_dev_ENSO |
numeric |
Deviation of Mean Temperature from ENSO Normals |
precip_sum_dev_ENSO |
numeric |
Deviation of Total Rainfall from ENSO Normals |
gdp |
numeric |
GDP in percentage point, percentage deviation from trend, detrended and seasonally adjusted |
ya |
numeric |
Agricultural GDP in percentage point, percentage deviation from trend, detrended and seasonally adjusted |
rer_hp |
numeric |
Real exchange rate, detrended using HP filter |
rer_dt_sa |
numeric |
Real exchange rate, detrended and seasonally adjusted |
r |
numeric |
Interest rate, in percentage point, detrended |
r_hp |
numeric |
Interest rate, in percentage point, detrended using HP filter |
pi |
numeric |
Inflation rate, in percentage point |
pia |
numeric |
Food inflation rate, in percentage point, seasonally adjusted |
ind_prod |
numeric |
Manufacturing Production, in percentage point, percentage deviation from trend, detrended and seasonally adjusted |
price_int |
numeric |
International commodity prices |
price_int_inf |
numeric |
Growth rate of international commodity prices |
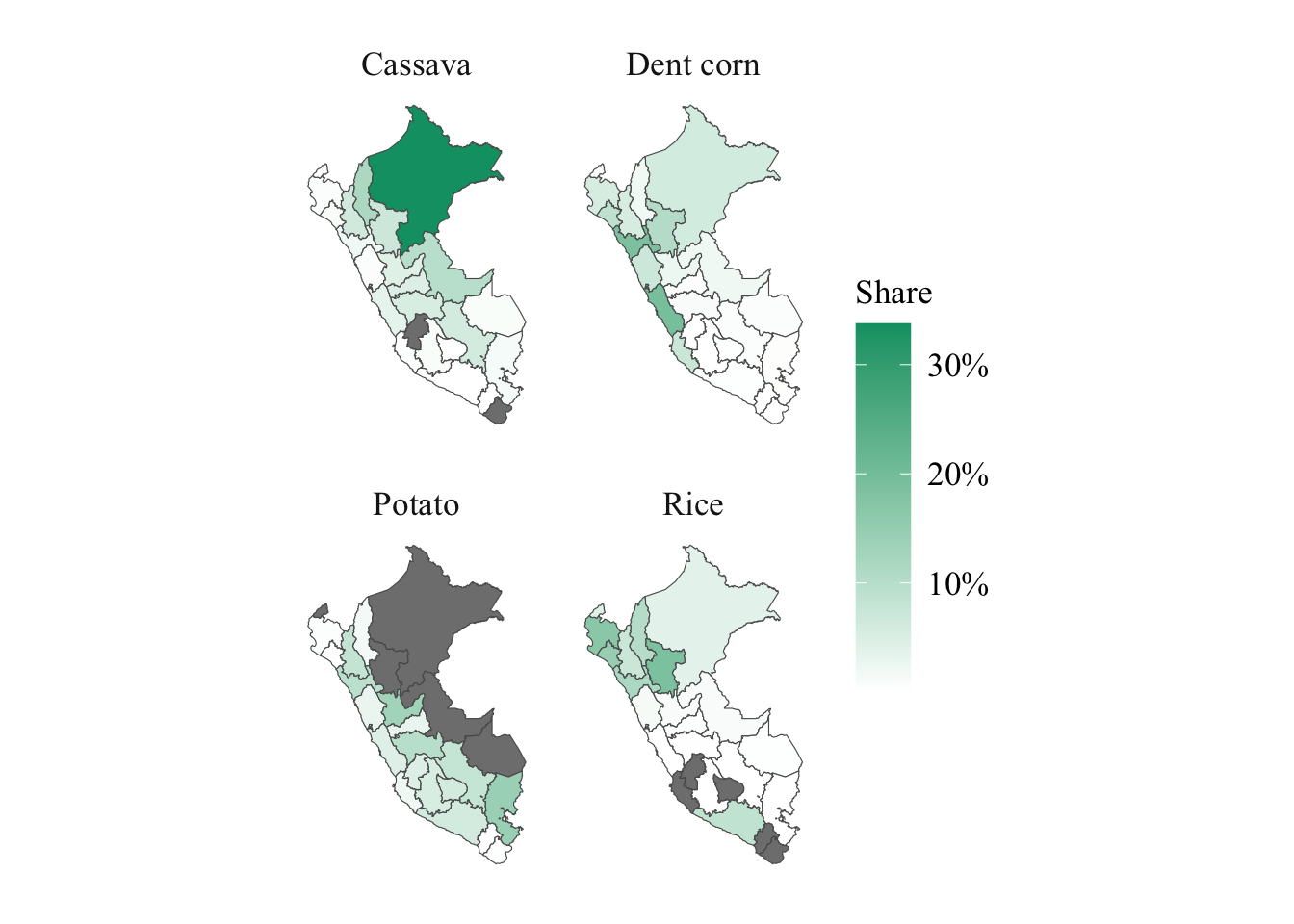
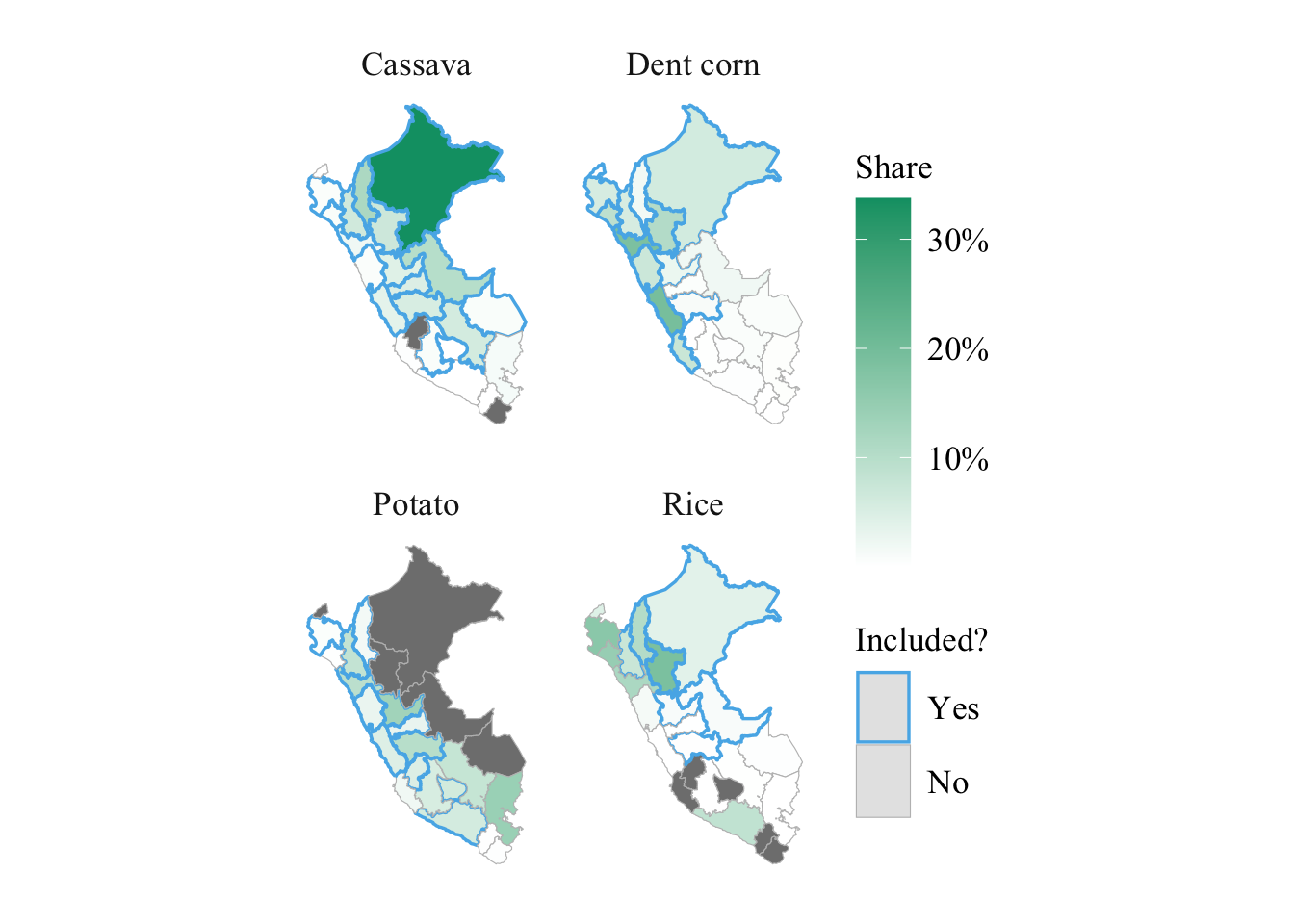
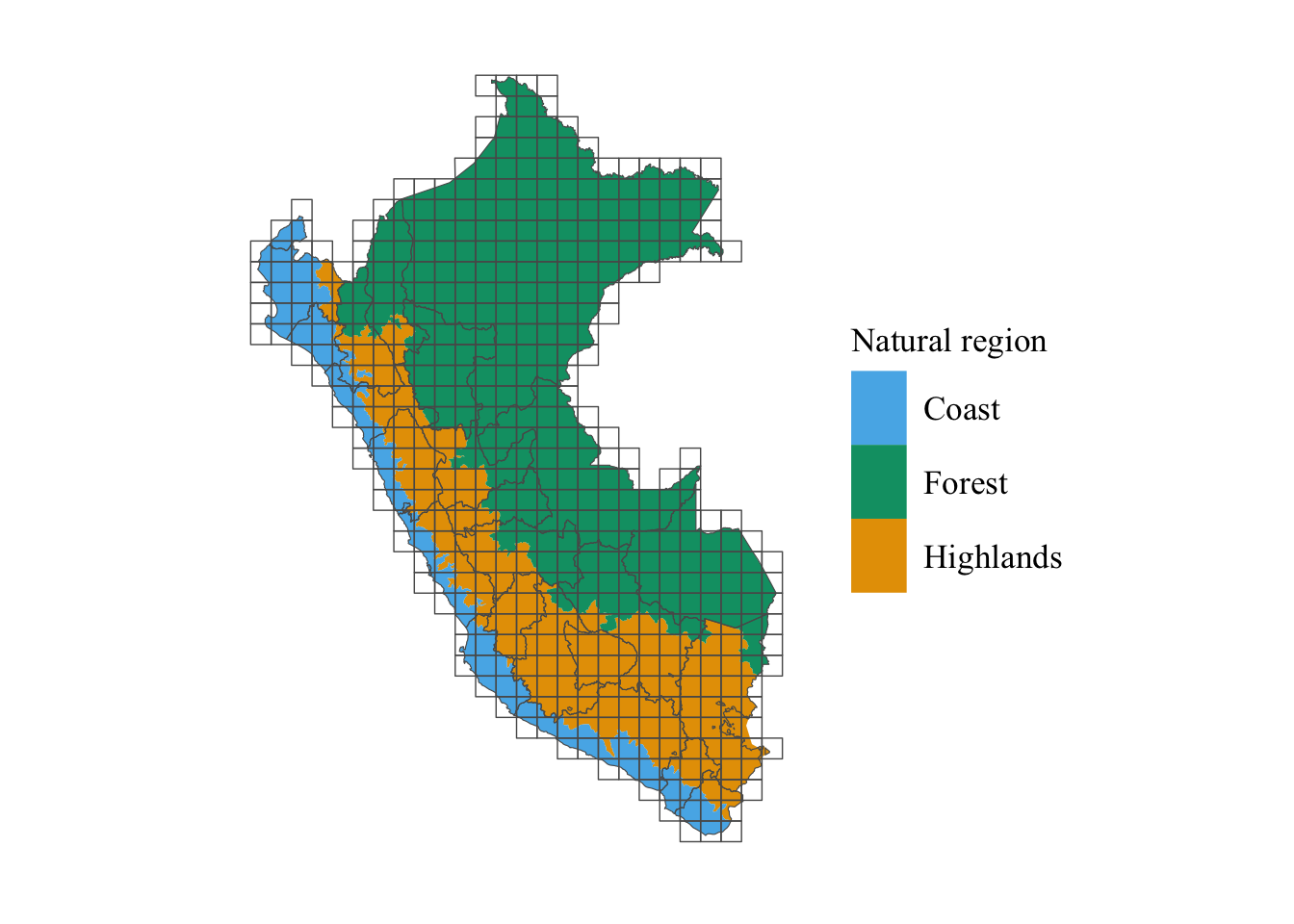
share_sierra |
numeric |
Share of highlands |
share_selva |
numeric |
Share of forest |
share_costa |
numeric |
Share of coast |