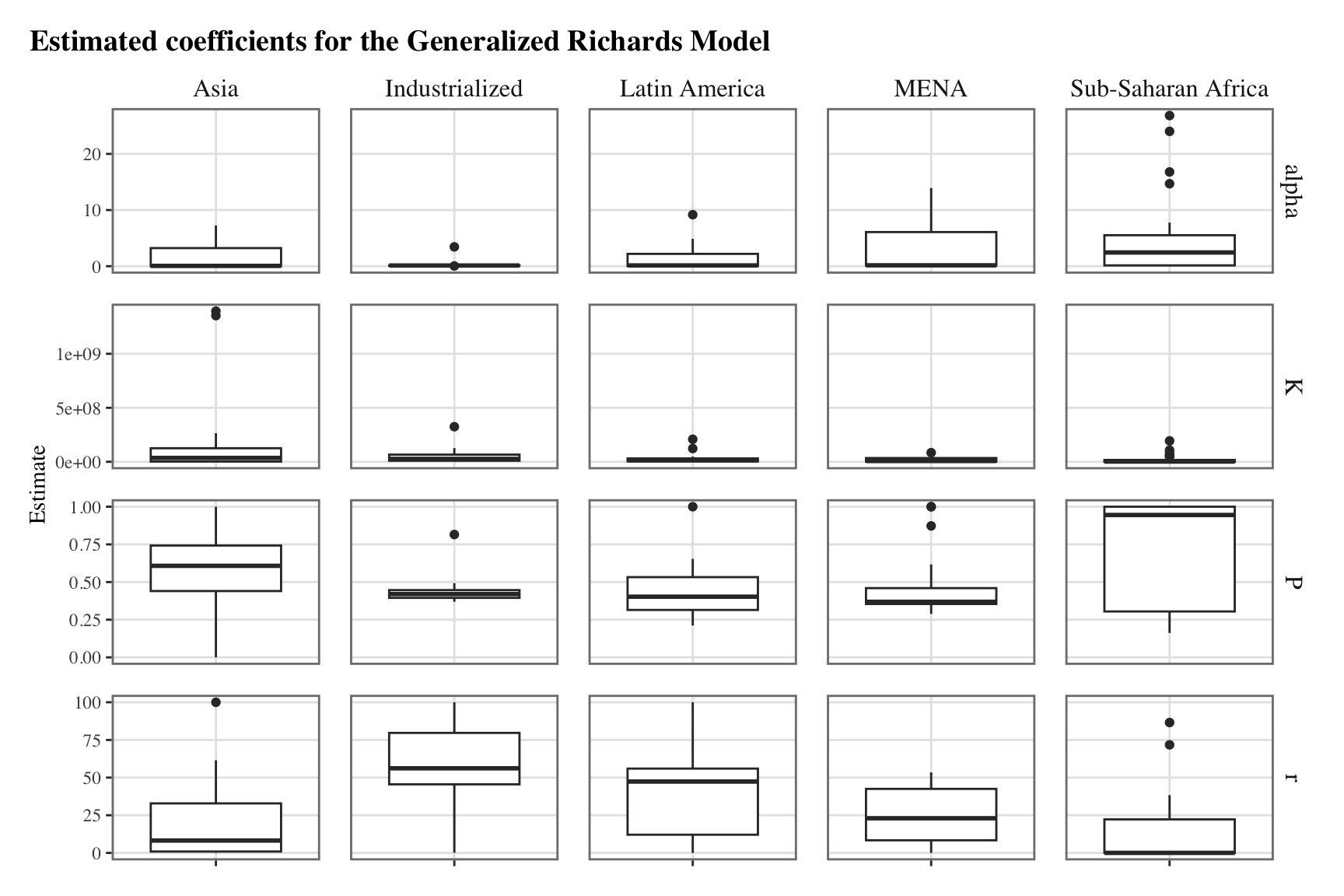
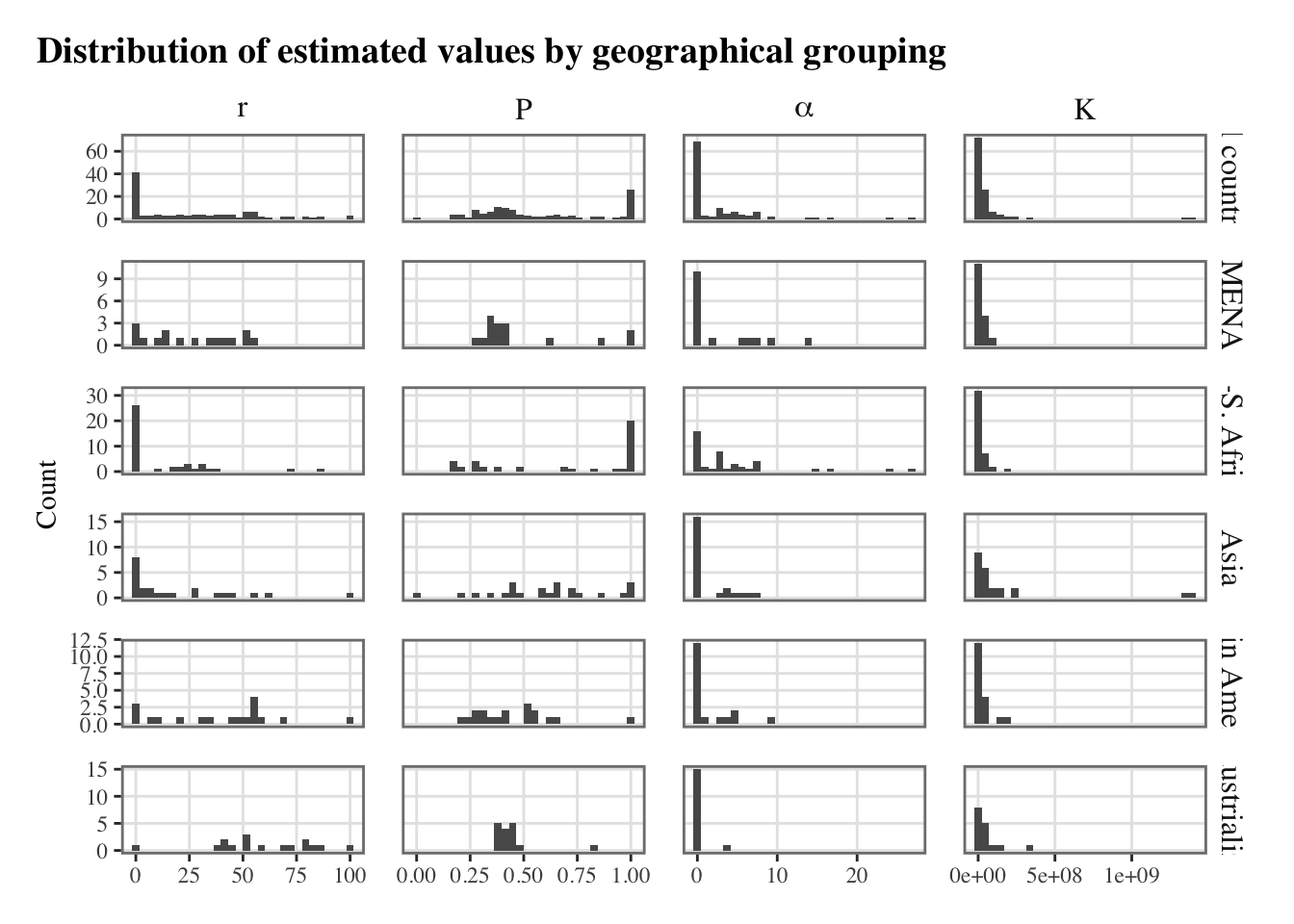
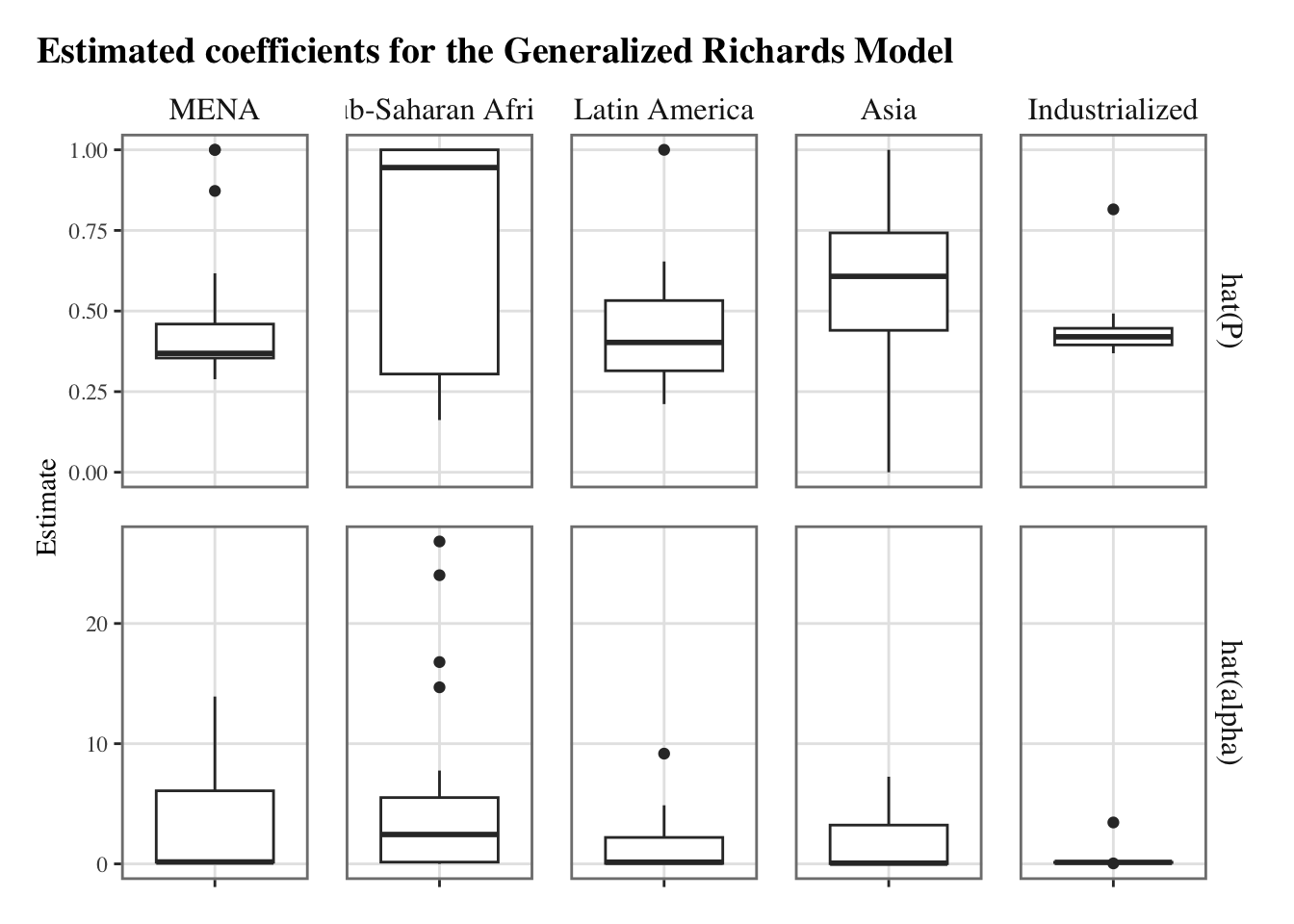
ggplot(data = estimates_nls |>left_join(list_countries) |>pivot_longer(cols =c(r, P, alpha, K)) |>group_by(name, group)) +geom_boxplot(mapping =aes(x = estim, y = value),na.rm =TRUE ) +facet_grid(name ~ group, scales ="free") +labs(x =NULL, y ="Estimate",title ="Estimated coefficients for the Generalized Richards Model" ) +theme_paper() +theme(axis.text.x =element_blank())
Joining with `by = join_by(country)`
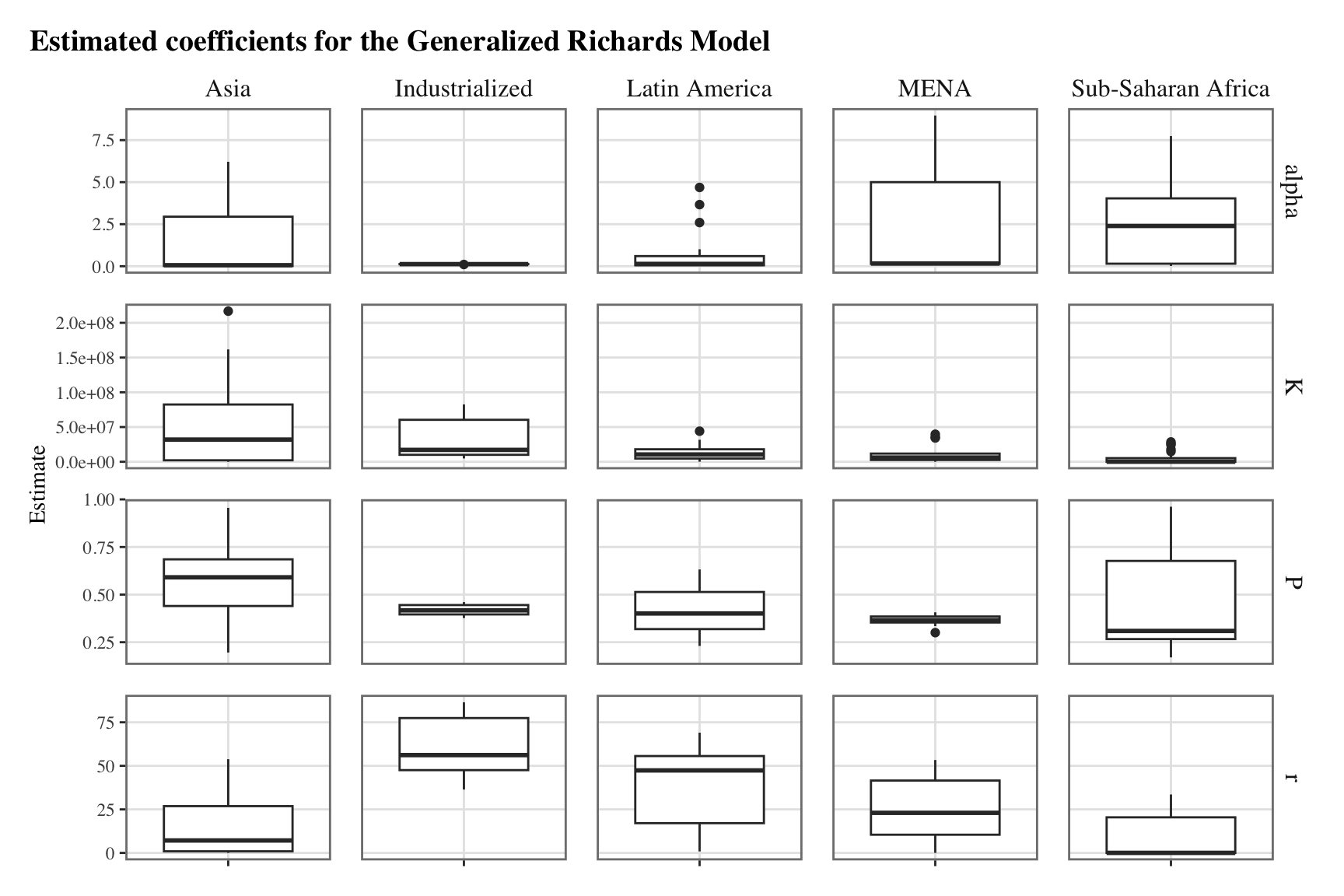
The same graph can be reproduced while removing outliers, to have a better idea of the variability between countries. We define a function to remove the outliers, as suggested by Andrew Baxter on Stack overflow:
filter_lims <-function(x) { l <-boxplot.stats(x)$stats[1] u <-boxplot.stats(x)$stats[5]for (i in1:length(x)) { x[i] <-ifelse(x[i]>l & x[i]<u, x[i], NA) }return(x)}
rmse |>left_join(list_countries, by ="country") |>group_by(group) |>summarise(rmse_nls =mean(nls),rmse_nls_med =median(nls) )
# A tibble: 5 × 3
group rmse_nls rmse_nls_med
<chr> <dbl> <dbl>
1 Asia 98445. 10801.
2 Industrialized 167568. 51634.
3 Latin America 40172. 11237.
4 MENA 21903. 13788.
5 Sub-Saharan Africa 4703. 1034.
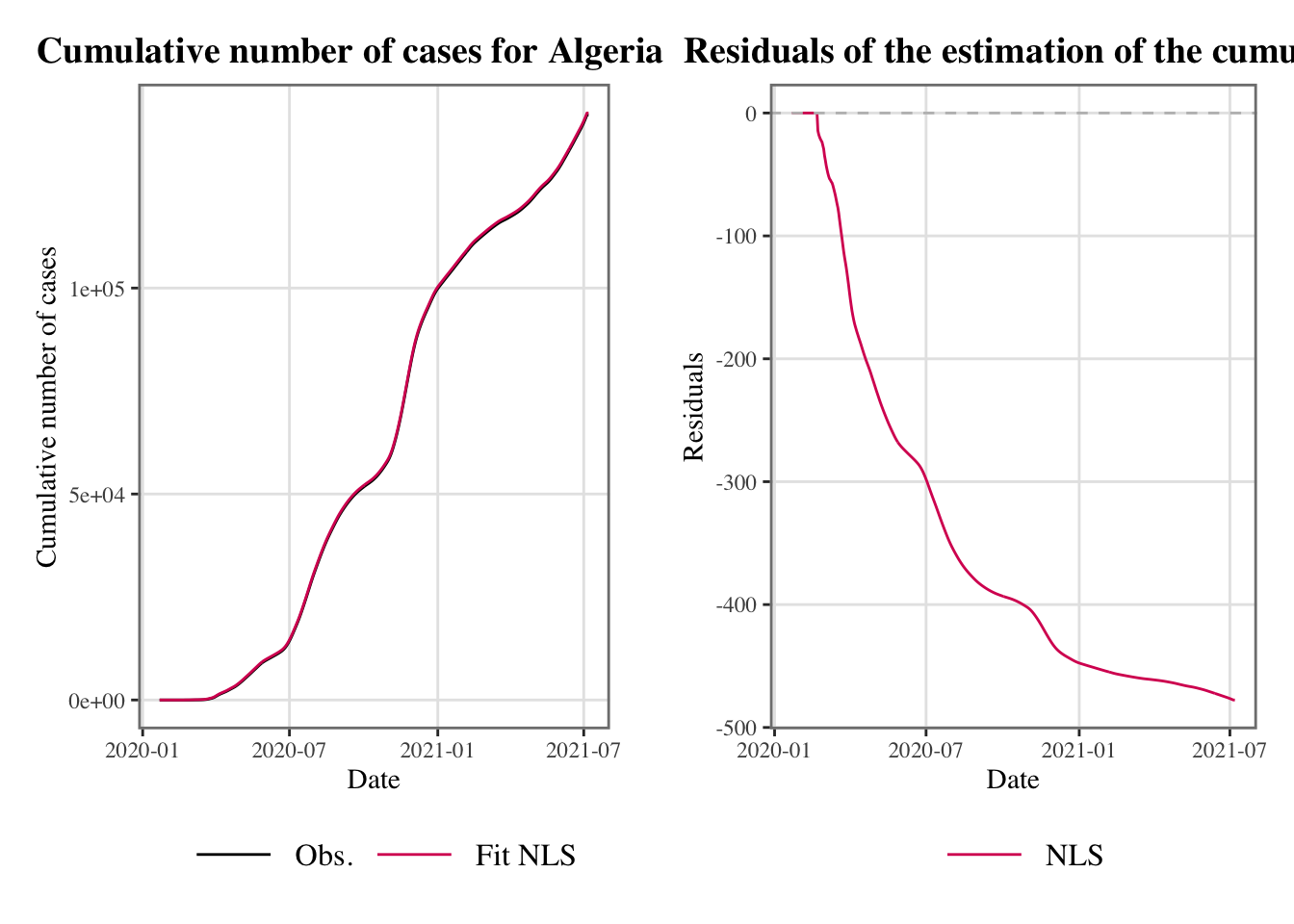
plot_fit <-function(country) { resul_country <-resul_fit_countries[[country]] dat_country <- resul_country$dat dat_country <- dat_country |>mutate(fit_nls = resul_country$nls$fit )# Obs and fitted values p_1 <-ggplot(data = dat_country |>select(date, C_m, fit_nls) |>pivot_longer(cols =c(C_m, fit_nls)) |>mutate(name =factor( name,levels =c("C_m", "fit_nls"),labels =c("Obs.", "Fit NLS") ) ),mapping =aes(x = date, y = value, colour = name) ) +geom_line() +scale_colour_manual(NULL,values =c("Obs."="black", "Fit NLS"="#D81B60") ) +labs(x ="Date", y ="Cumulative number of cases",title =str_c("Cumulative number of cases for ", country) ) +theme_paper() +theme(legend.key.height =unit(1, "line"),legend.key.width =unit(2.5, "line"),legend.box ="horizontal" ) +guides(colour =guide_legend(override.aes =list(size =1.8)))# Residuals p_2 <-ggplot(data = dat_country |>select(date, C_m, fit_nls) |>pivot_longer(cols =c(fit_nls)) |>mutate(error = C_m - value) |>mutate(name =factor( name,levels =c("fit_nls"),labels =c("NLS") ) ),mapping =aes(x = date, y = error, colour = name) ) +geom_line() +geom_hline(yintercept =0, linetype ="dashed", colour ="grey") +scale_colour_manual(NULL, values =c("NLS"="#D81B60")) +labs(x ="Date", y ="Residuals",title =str_c("Residuals of the estimation of the cumulative number of cases for ", country ) ) +theme_paper() +theme(legend.key.height =unit(1, "line"),legend.key.width =unit(2.5, "line"),legend.box ="horizontal" ) +guides(colour =guide_legend(override.aes =list(size =1.8))) cowplot::plot_grid(p_1, p_2)}
plot_fit("Algeria")
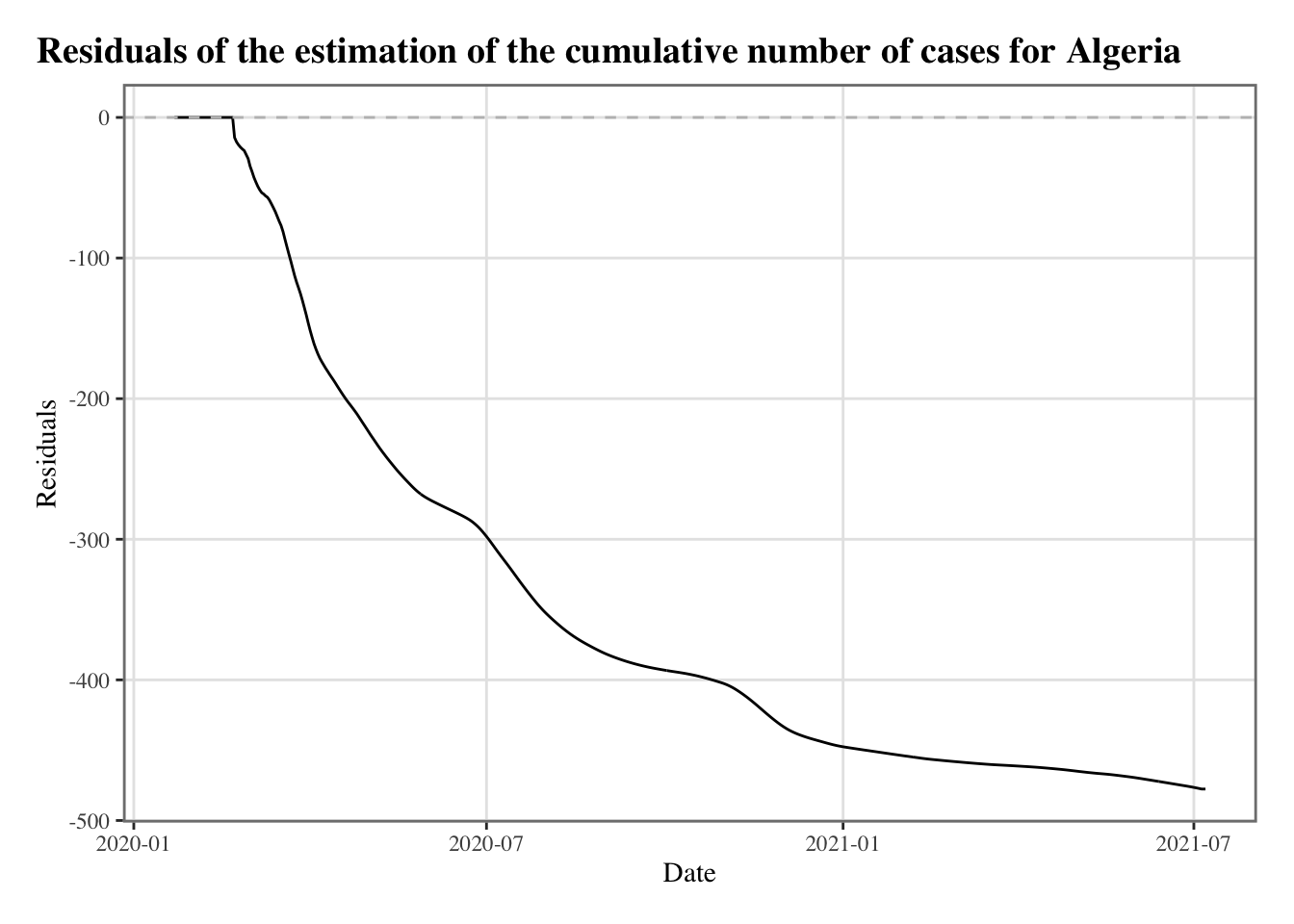
Let us focus on the residuals:
plot_fit_2 <-function(country) { resul_country <-resul_fit_countries[[country]] dat_country <- resul_country$dat dat_country <- dat_country |>mutate(fit_nls = resul_country$nls$fit)# Residuals p_2 <-ggplot(data = dat_country |>select(date, C_m, fit_nls) |>pivot_longer(cols =c(fit_nls)) |>mutate(error = C_m - value),mapping =aes(x = date, y = error)) +geom_line() +geom_hline(yintercept =0, linetype ="dashed", colour ="grey") +scale_colour_manual(NULL, values =c("NLS"="#D81B60")) +labs(x ="Date", y ="Residuals",title =str_c("Residuals of the estimation of the cumulative number of cases for ",country) ) +theme_paper() +theme(legend.key.height =unit(1, "line"),legend.key.width =unit(2.5, "line"),legend.box ="horizontal") +guides(colour =guide_legend(override.aes =list(size =1.8))) p_2}
plot_fit_2("Algeria")
4.2 Descriptive Statistics of the Estimates
estimates_all <- estimates_nls |>left_join(list_countries, by ="country")
library(kableExtra)
Attaching package: 'kableExtra'
The following object is masked from 'package:dplyr':
group_rows
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
4.3 Maps
Let us define a theme for maps:
#' Theme for maps with ggplot2#'#' @param ... arguments passed to the theme function#' @export#' @importFrom ggplot2 element_rect element_text element_blank element_line unit#' reltheme_map_paper <-function(...) {theme(text =element_text(family ="Times"),plot.background =element_rect(fill ="transparent", color =NA),panel.background =element_rect(fill ="transparent", color =NA),panel.border =element_blank(),axis.title =element_blank(),axis.text =element_blank(),axis.ticks =element_blank(), axis.line =element_blank(),plot.title.position ="plot",legend.text =element_text(size =rel(1.2)),legend.title =element_text(size =rel(1.2)),legend.background =element_rect(fill="transparent", color =NULL),legend.key =element_blank(),legend.key.height =unit(2, "line"),legend.key.width =unit(1.5, "line"),strip.background =element_rect(fill =NA),panel.spacing =unit(1, "lines"),panel.grid.major =element_blank(),panel.grid.minor =element_blank(),plot.margin =unit(c(1, 1, 1, 1), "lines"),strip.text =element_text(size =rel(1.2)) )}
A Shapefile that allows us to display the level 0 world administrative boundaries, freely available on the online open data platform “opendatasoft”, can be loaded:
library(sf)
Linking to GEOS 3.11.0, GDAL 3.5.3, PROJ 9.1.0; sf_use_s2() is TRUE
There are some mismatching country names between the map file and the epidemic data. The names from the map file can be manually changed:
world_map <- world_map |>mutate(name =recode( name, # old = new"Brunei Darussalam"="Brunei","Côte d'Ivoire"="Cote d'Ivoire","Democratic Republic of the Congo"="Democratic Republic of Congo","Swaziland"="Eswatini","Iran (Islamic Republic of)"="Iran","Lao People's Democratic Republic"="Laos","Russian Federation"="Russia","Republic of Korea"="South Korea","Syrian Arab Republic"="Syria","United Republic of Tanzania"="Tanzania","U.K. of Great Britain and Northern Ireland"="United Kingdom","United States of America"="United States" ) )
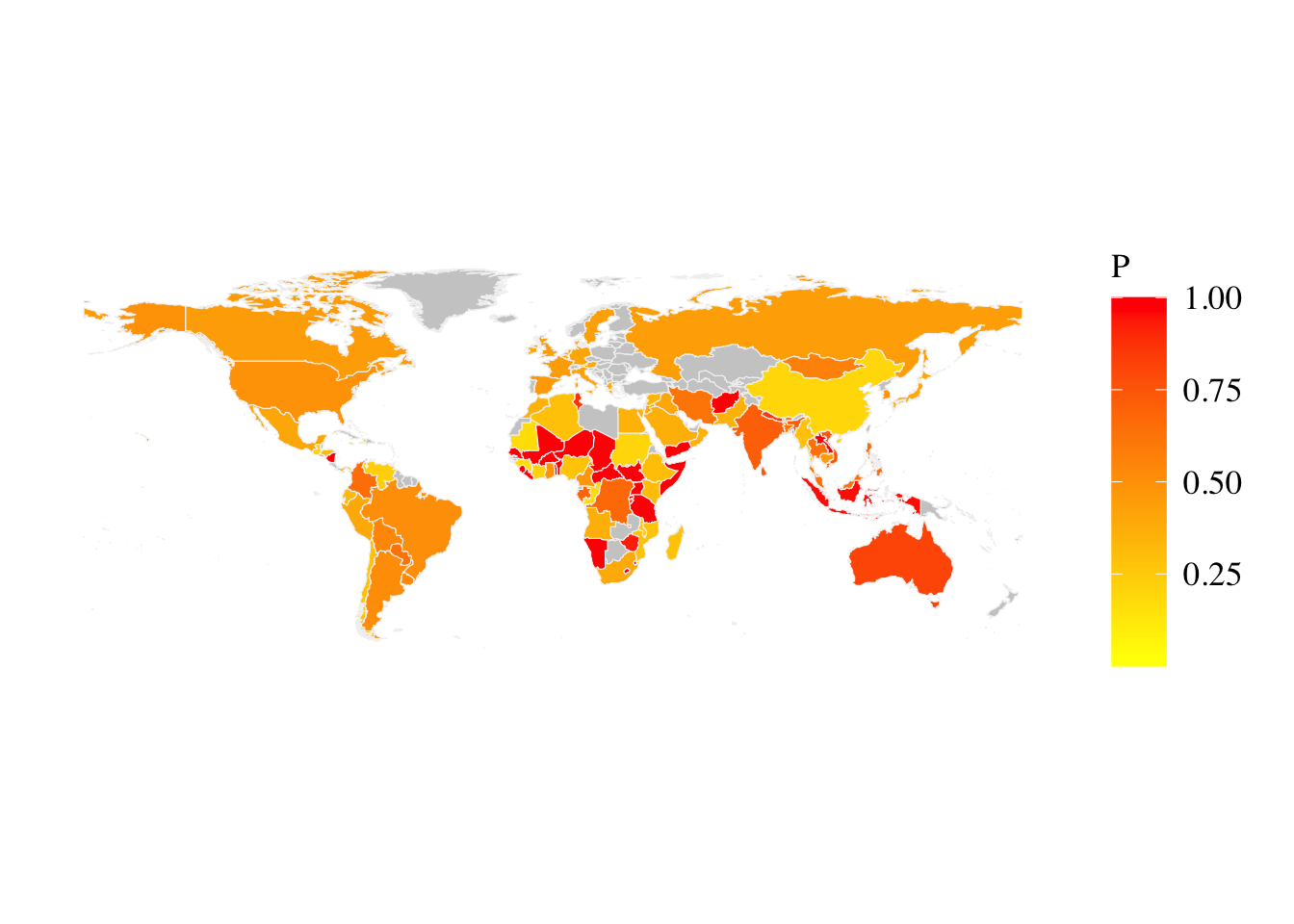
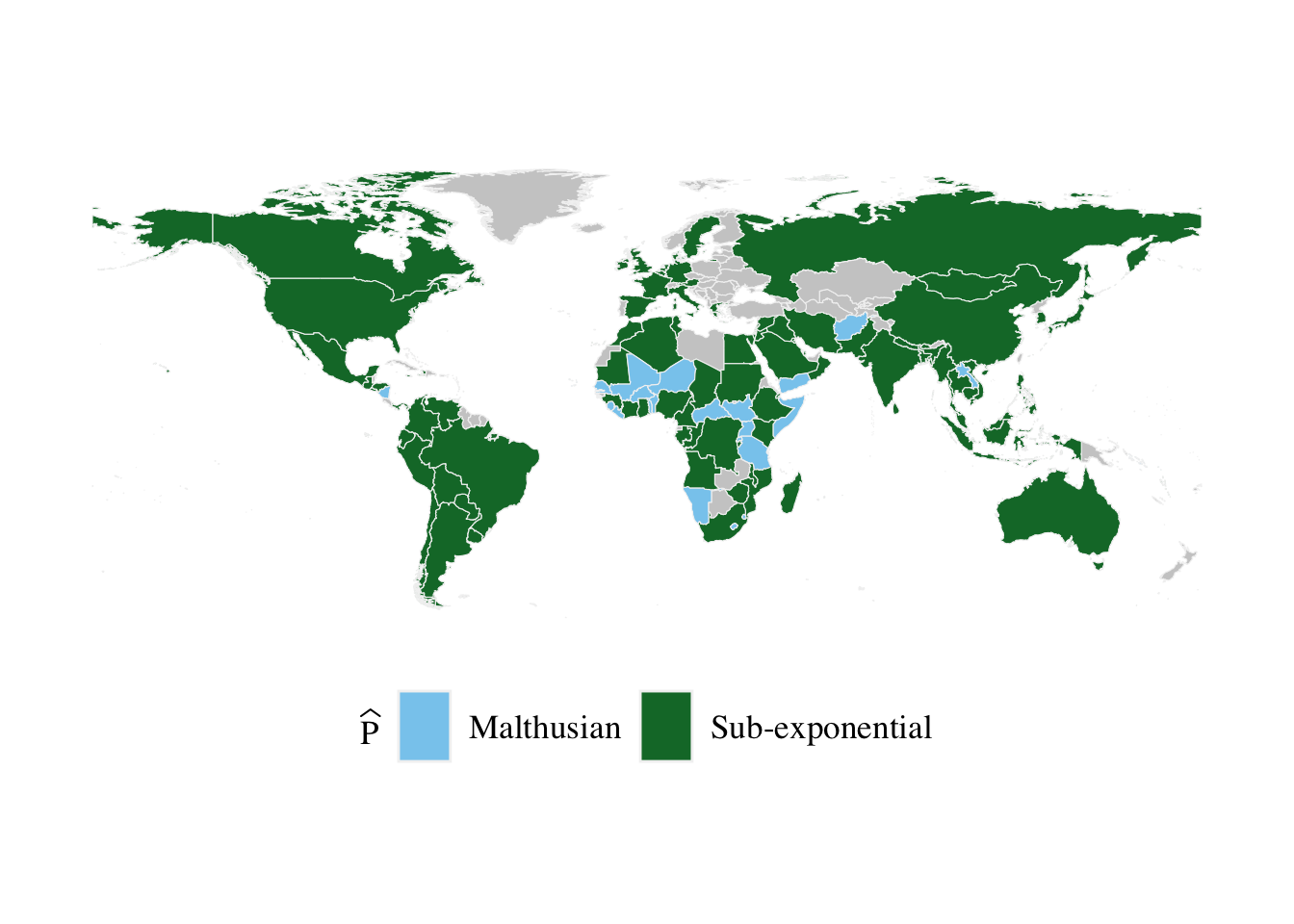
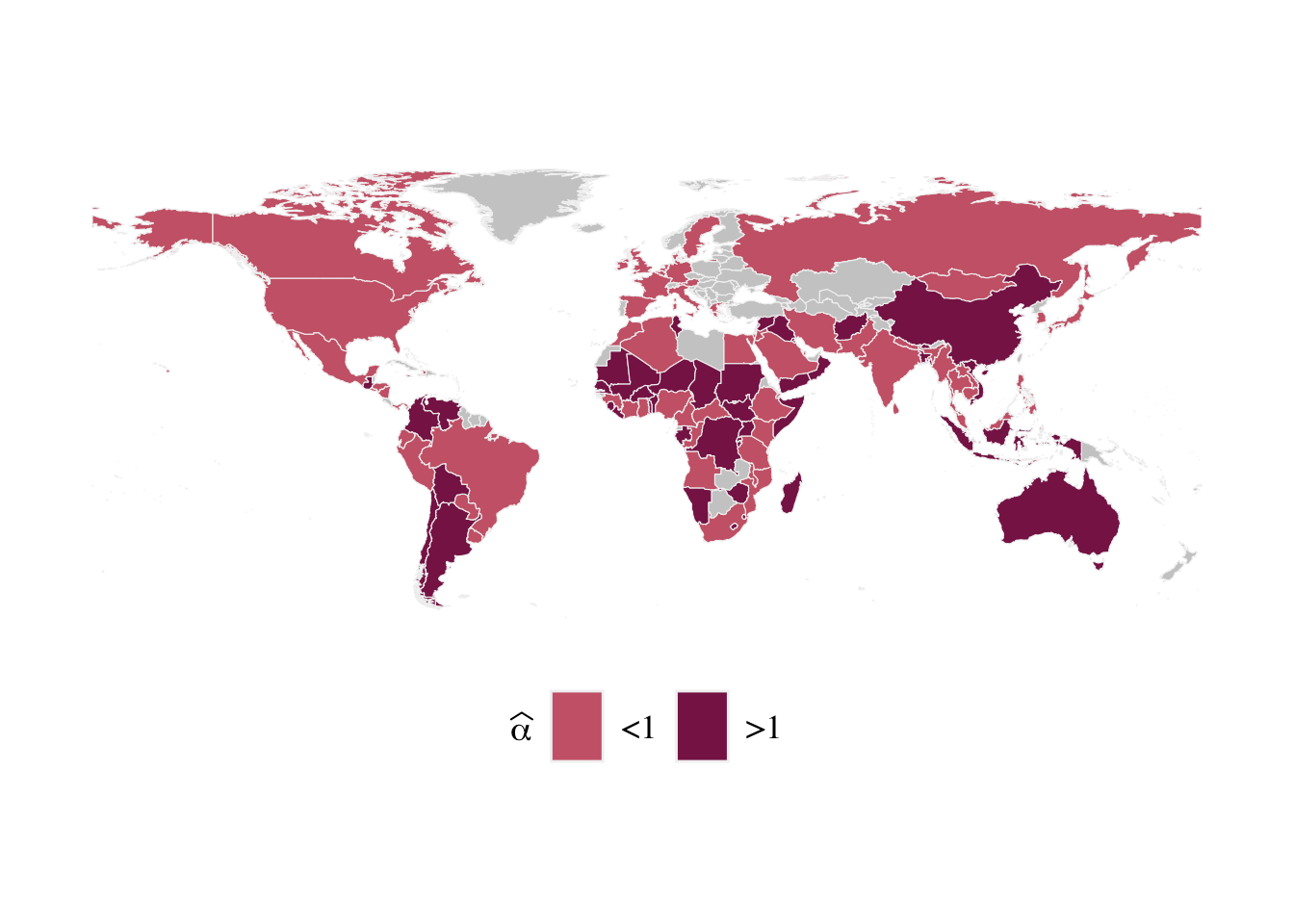
Let us add the estimated values for each country to the map data: