Probabilistic Scores of Classifiers, Calibration is not Enough
calibration
classification
trees
machine learning
arxiv
working paper
Agathe
Arthur
François
Emmanuel
With Agathe Fernandes Machado, Arthur Charpentier, François Hu and Emmanuel Flachaire, we have uploaded our new working paper on arXiv : https://arxiv.org/abs/2408.03421
Abstract
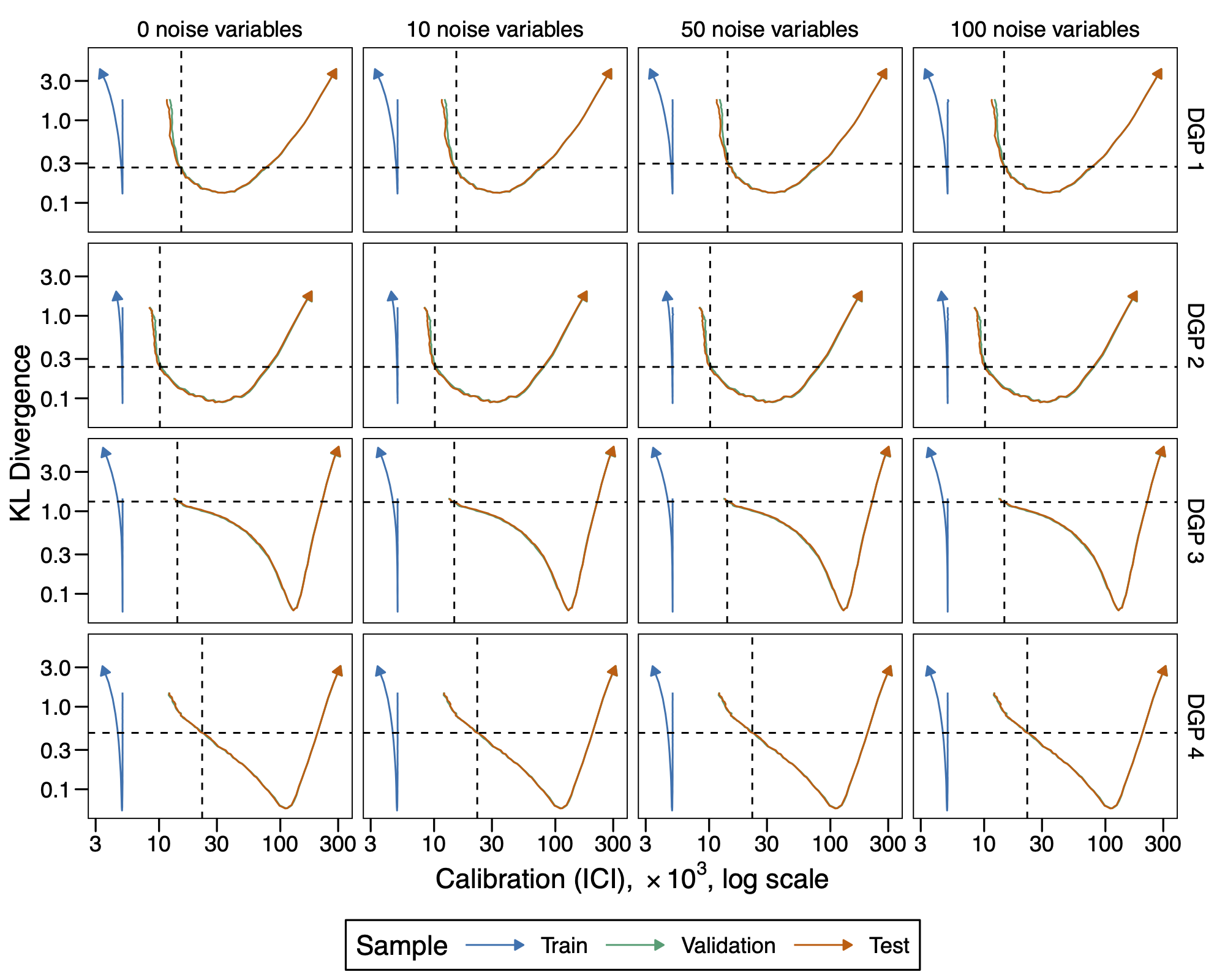
When it comes to quantifying the risks associated with decisions made using a classifier, it is essential that the scores returned by the classifier accurately reflect the underlying probability of the event in question. The model must then be well-calibrated. This is particularly relevant in contexts such as assessing the risks of payment defaults or accidents, for example. Tree-based machine learning techniques like random forests and XGBoost are increasingly popular for risk estimation in the industry, though these models are not inherently well-calibrated. Adjusting hyperparameters to optimize calibration metrics, such as the Integrated Calibration Index (ICI), does not ensure score distribution aligns with actual probabilities. Through a series of simulations where we know the underlying probability, we demonstrate that selecting a model by optimizing Kullback-Leibler (KL) divergence should be a preferred approach. The performance loss incurred by using this model remains limited compared to that of the best model chosen by AUC. Furthermore, the model selected by optimizing KL divergence does not necessarily correspond to the one that minimizes the ICI, confirming the idea that calibration is not a sufficient goal. In a real-world context where the distribution of underlying probabilities is no longer directly observable, we adopt an approach where a Beta distribution a priori is estimated by maximum likelihood over 10 UCI datasets. We show, similarly to the simulated data case, that optimizing the hyperparameters of models such as random forests or XGBoost based on KL divergence rather than on AUC allows for a better alignment between the distributions without significant performance loss. Conversely, minimizing the ICI leads to substantial performance loss and suboptimal KL values.
A replication ebook is available on Agathe’s Github Page: codes (ebook)
The corresponding R codes are available on Agathe’s GitHub: GitHub