From Uncertainty to Precision: Enhancing Binary Classifier Performance through Calibration
Séminaire STATQAM – Université du Québec à Montréal
Classification and Confidence
 |
 |
 |
 |
| female (0.984) | female (0.983) | female (0.982) | female (0.960) |
| male (0.016) | male (0.017) | male (0.018) | male (0.040) |
 |
 |
 |
 |
| female (0.009) | female (0.013) | female (0.014) | female (0.015) |
| male (0.991) | male (0.987) | male (0.986) | male (0.985) |
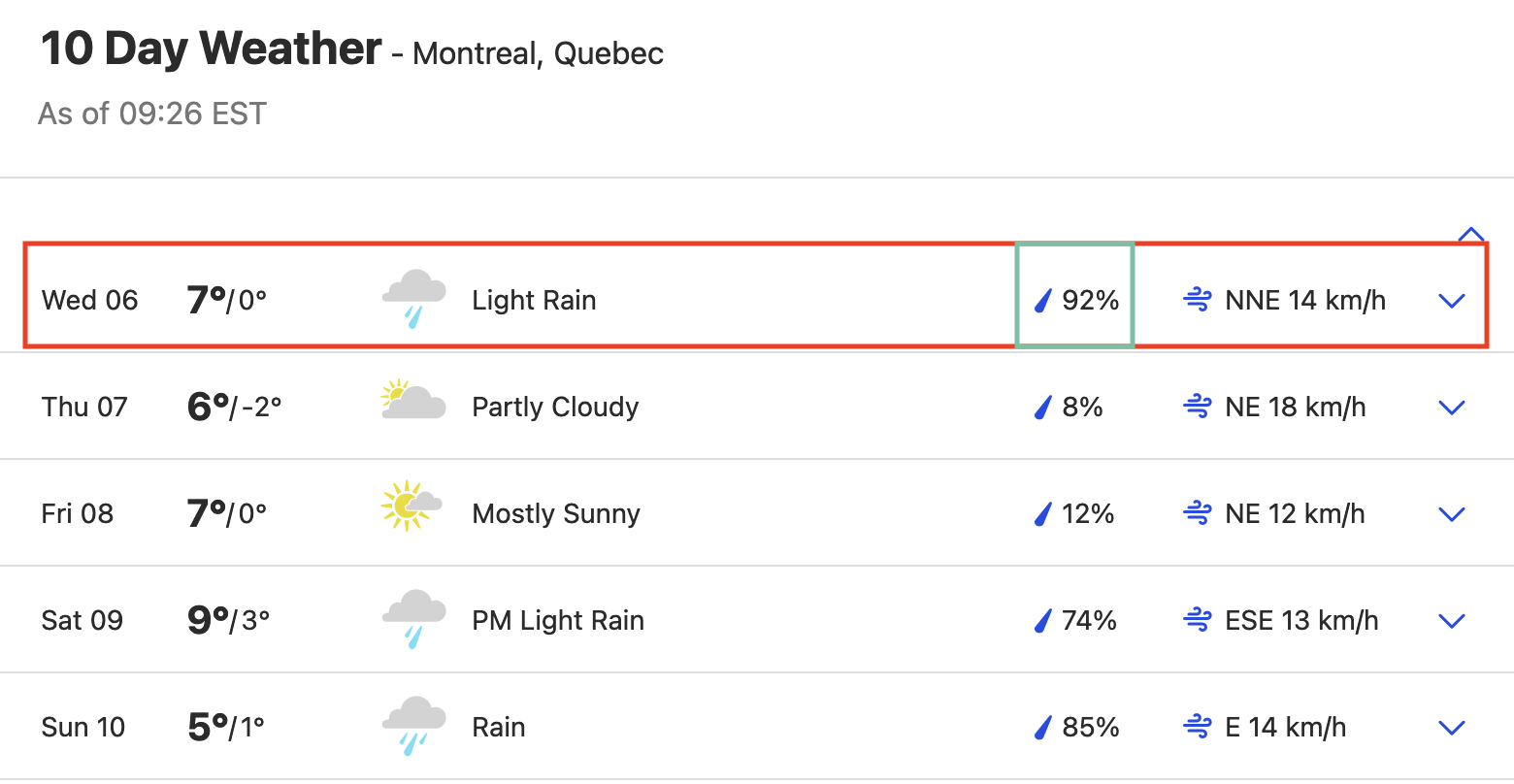
Intuition: Weather Forecasts
Within this sequence, we focus on days where \(\hat{s}(\mathbf{x}_i)\) closely approximates 30%.
By assuming an infinite sequence, we can determine the long-term proportion \(p\) of days where the forecasted event actually occurred.
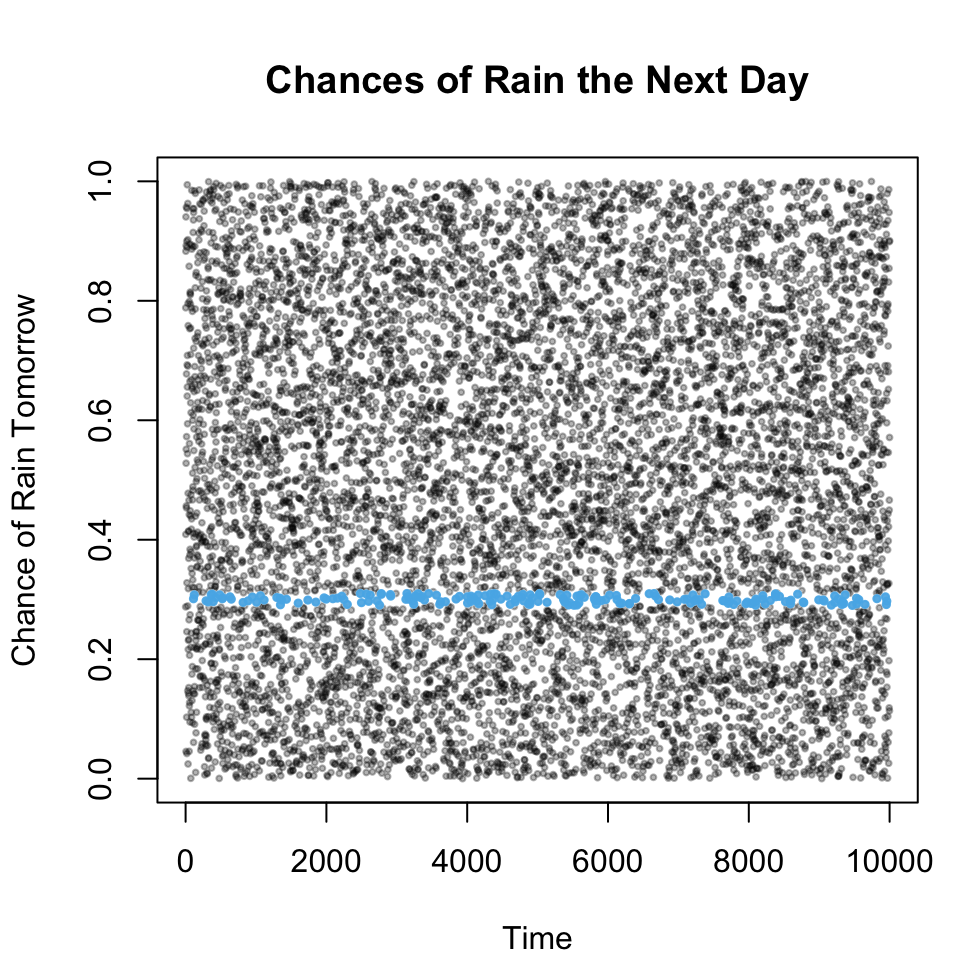
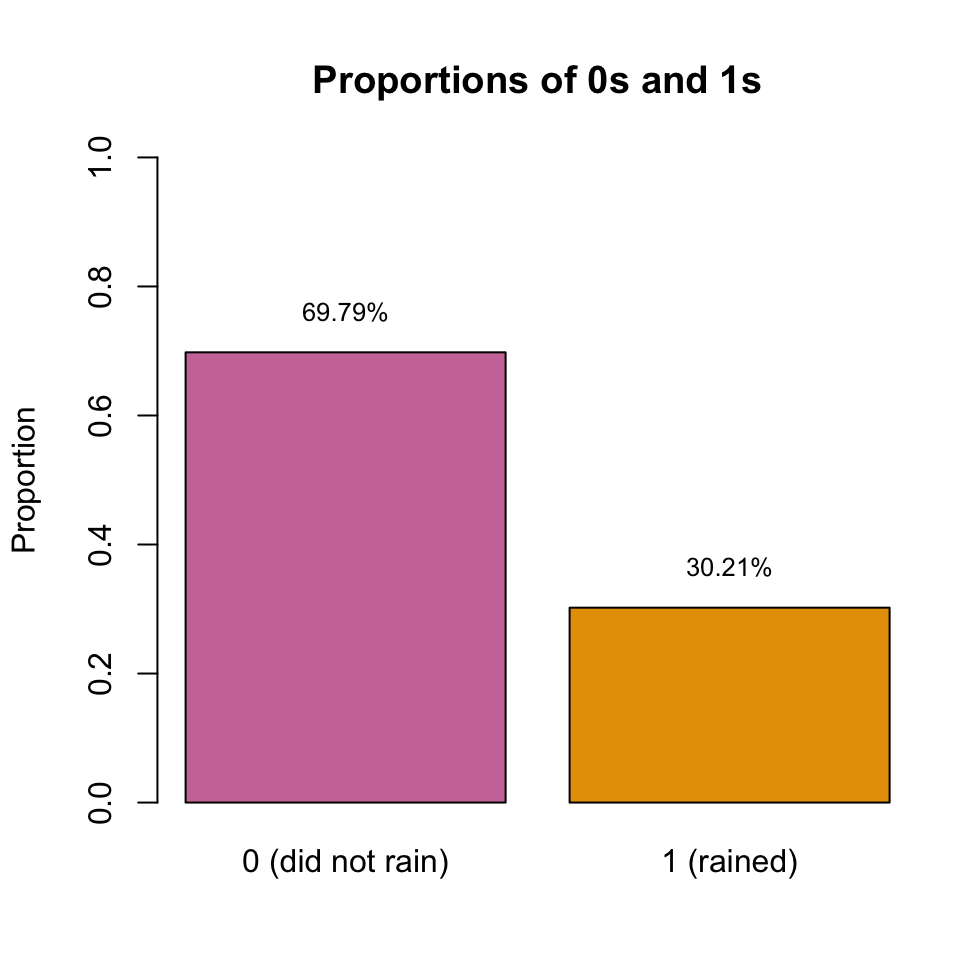
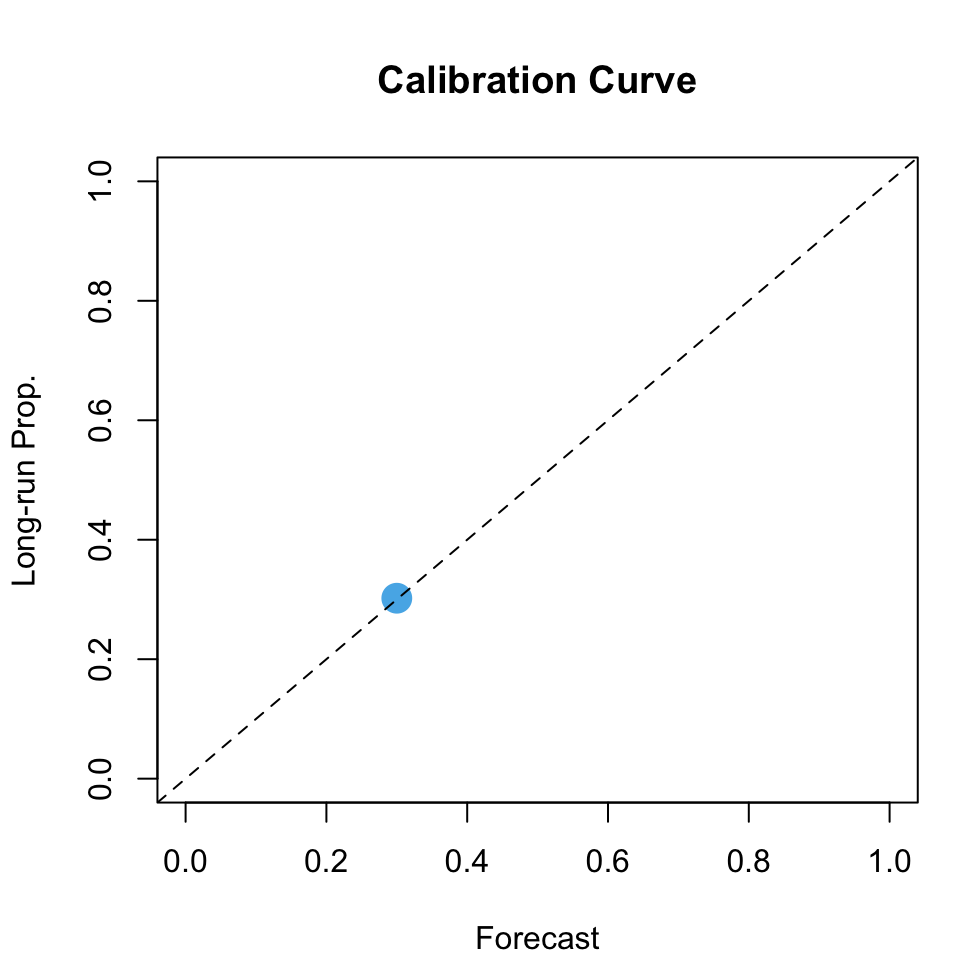
Intuition: Weather Forecasts
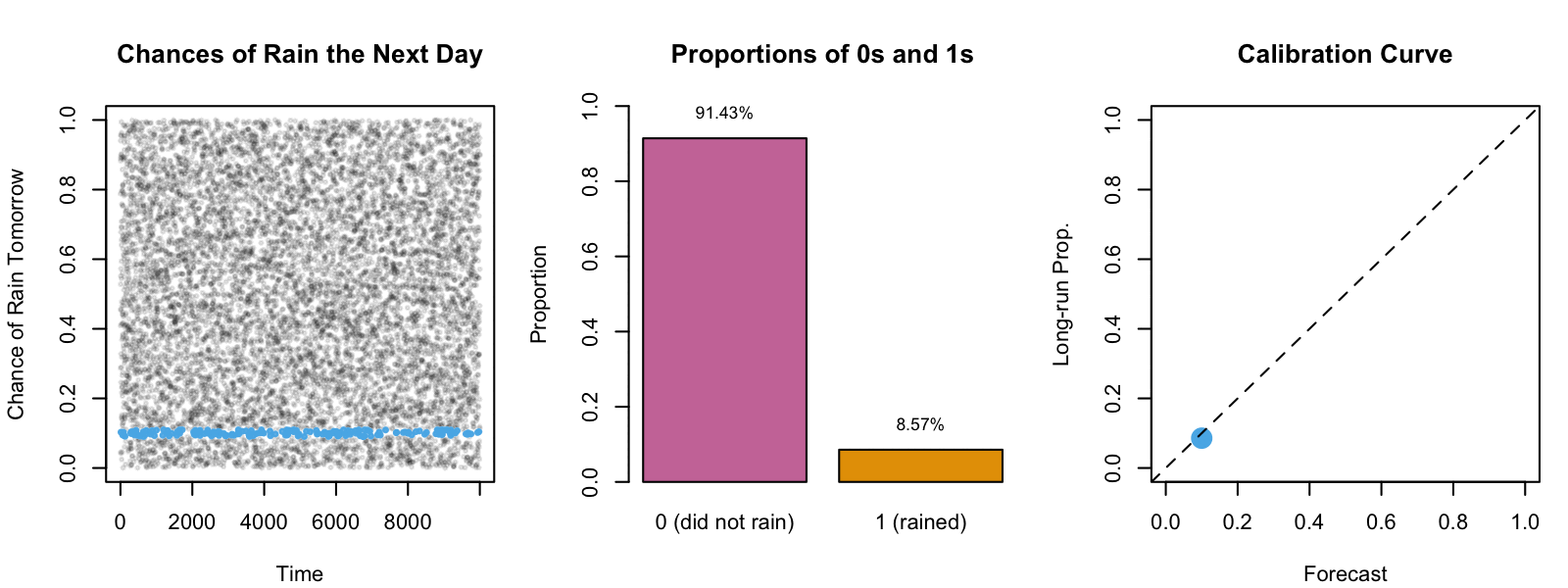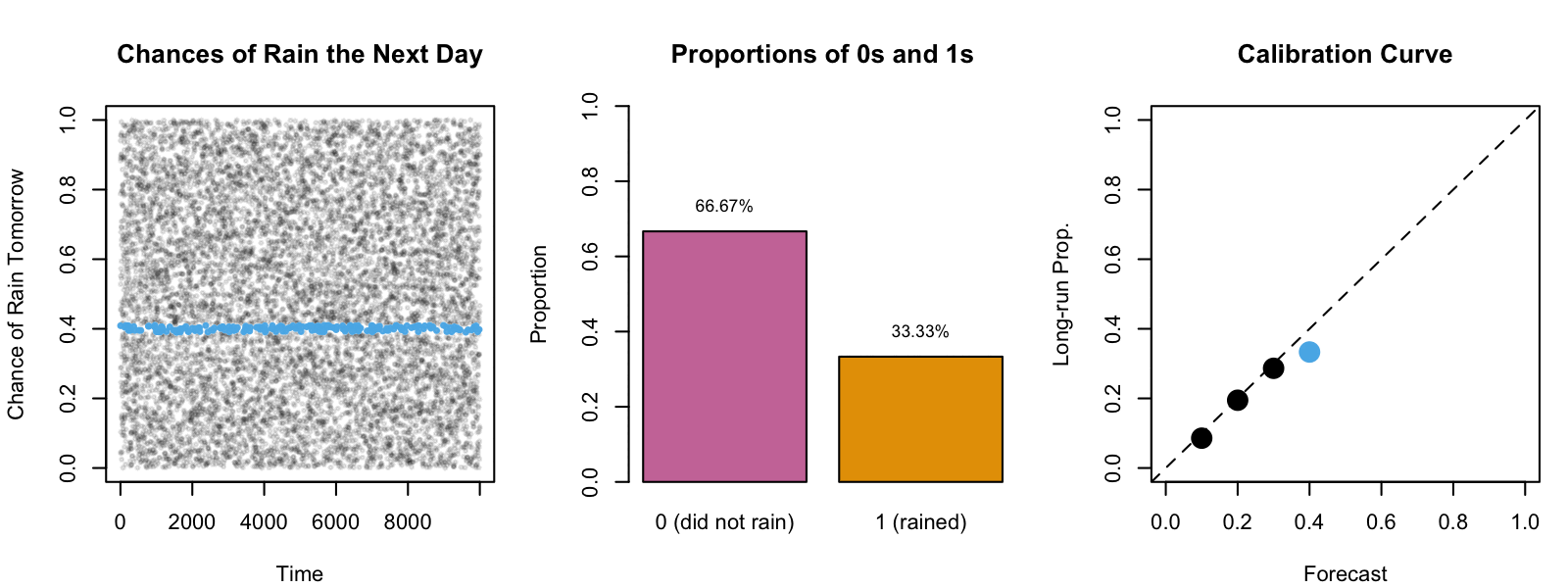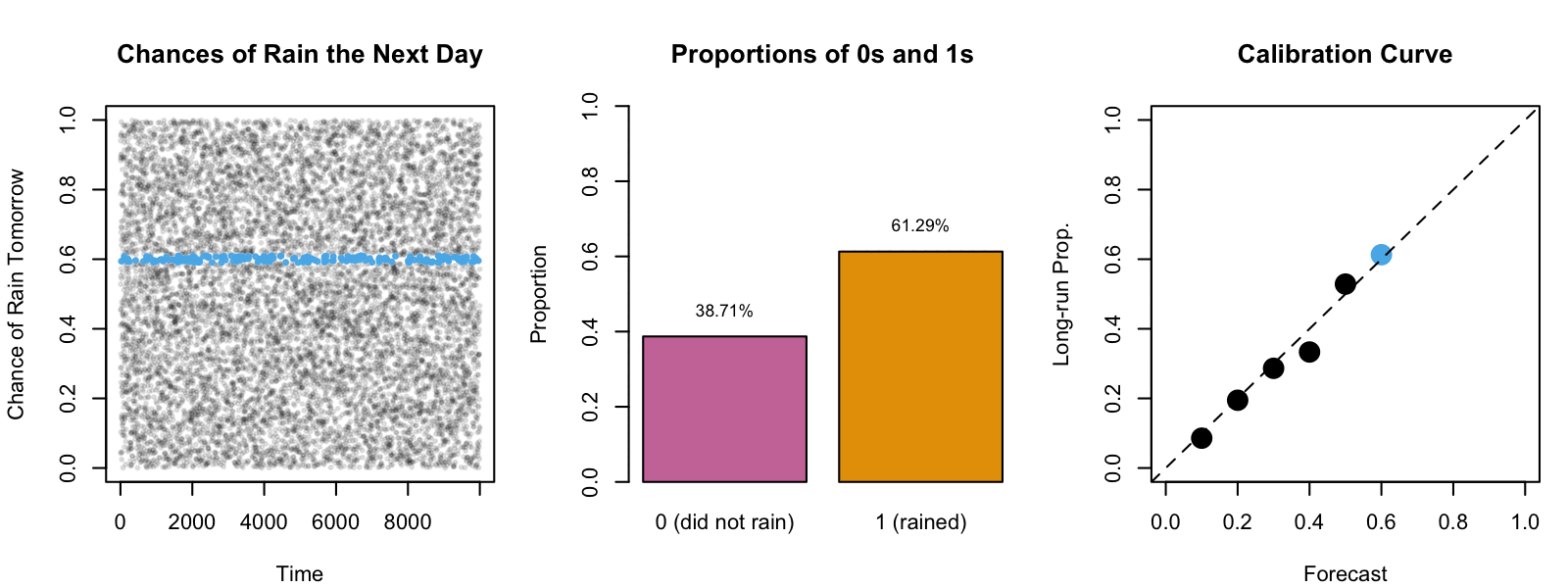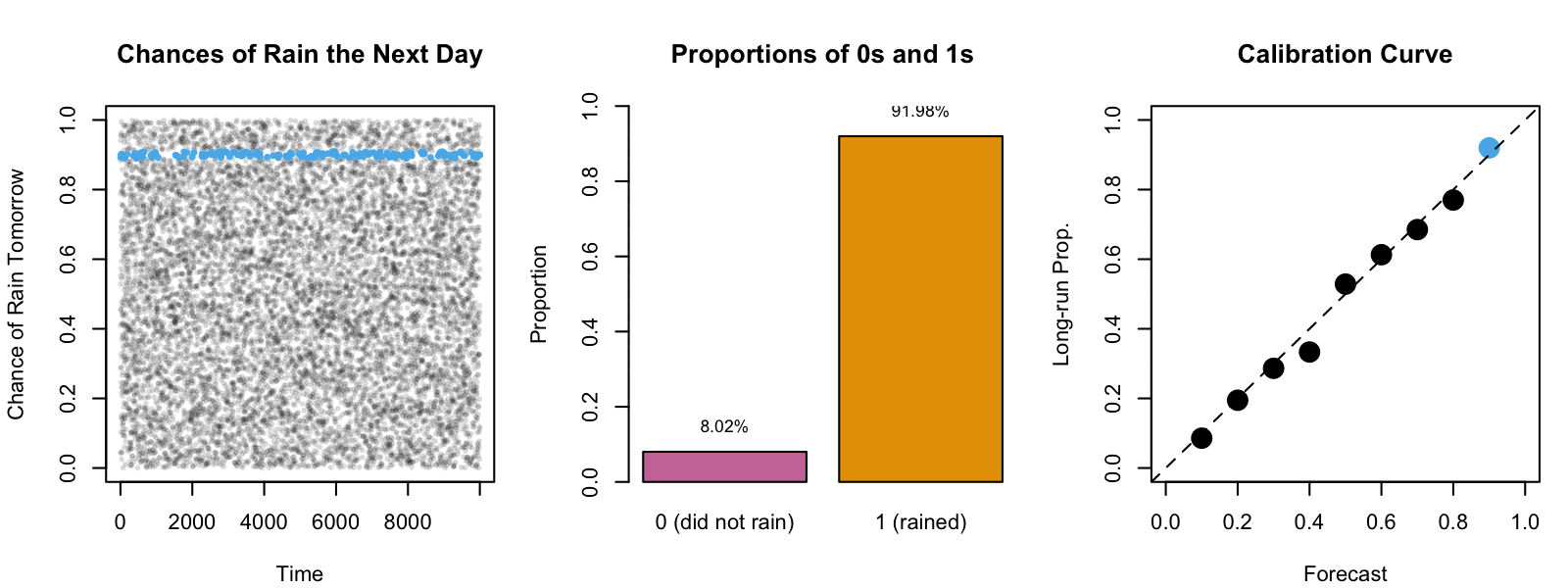
Figure 2: Example: Calibration of Weather Forecasts
Distortions
We examine variations in \(\{1/3, 1, 3\}\) for \(\alpha\) and \(\gamma\)
For each of the 6 scenarios, we generate 200 samples of \(2,000\) obs.
![]()
Impacts: Calibration Metrics
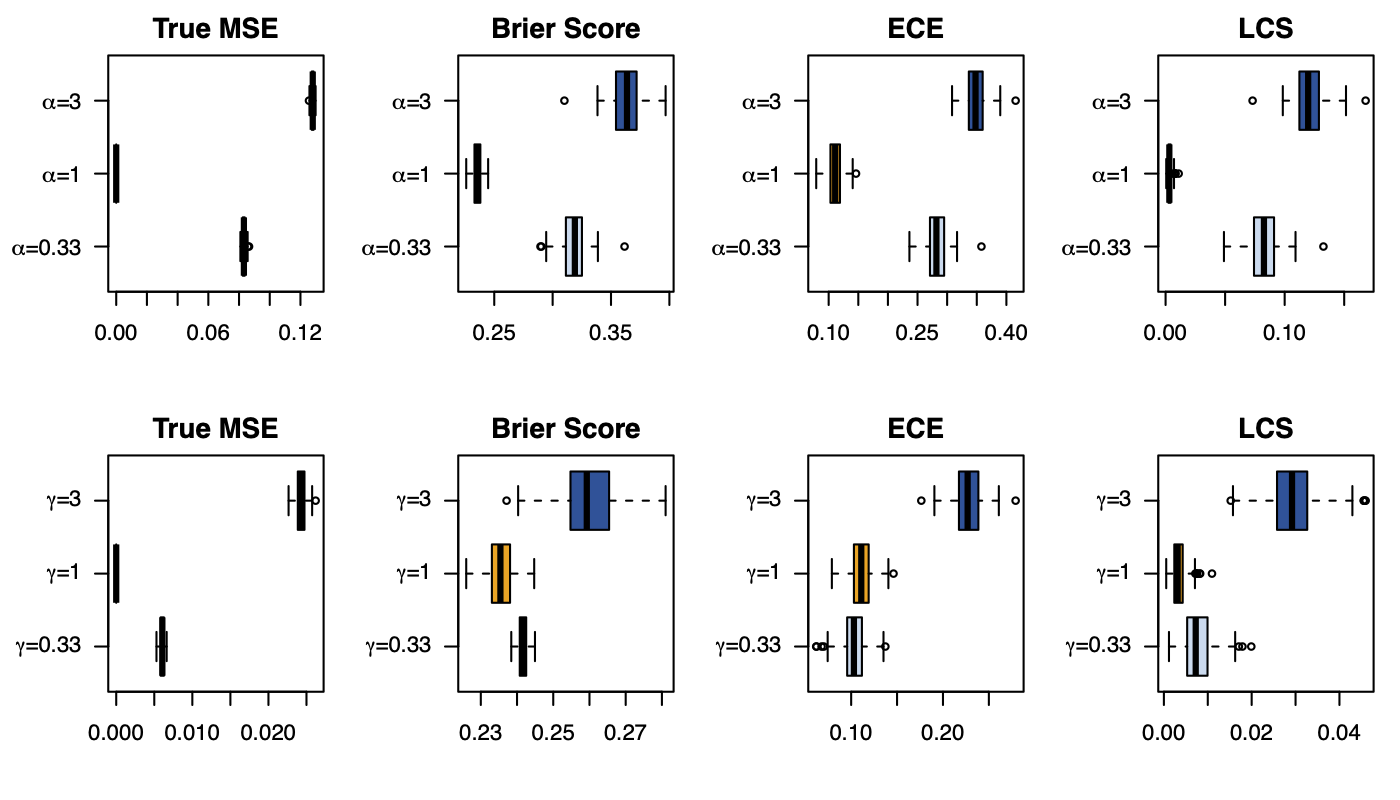
Figure 4: Calibration Metrics on 200 Simulations for each Value of \(\alpha\) (top) or \(\gamma\) (bottom).
Impacts: Calibration Curves
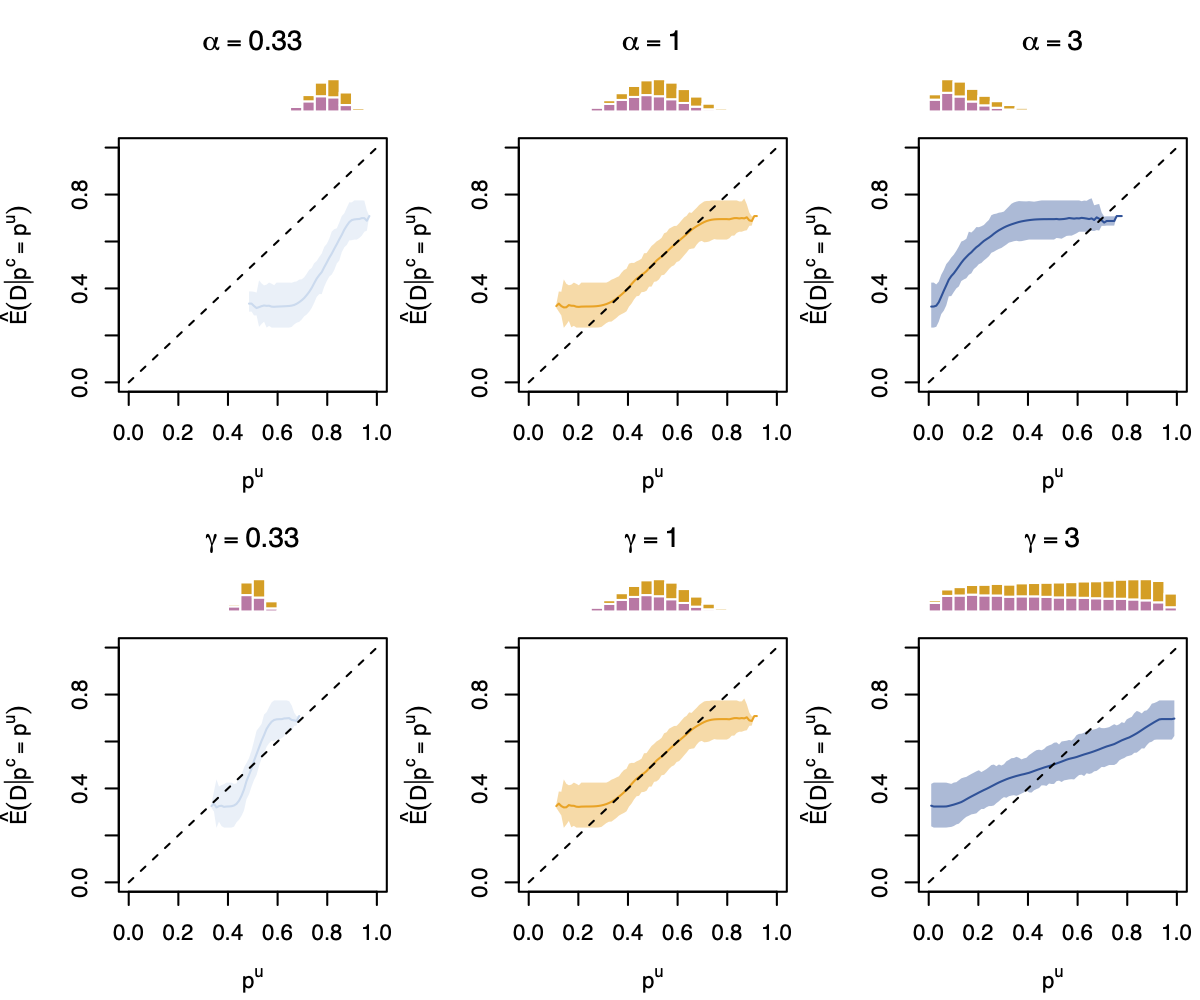
Figure 5: Calibration Curve Obtained with Local Regression, on 200 simulations for each Value of \(\alpha\) (top) or \(\gamma\) (bottom). Distribution of the true probabilities are shown in the histograms (gold for \(d=1\), purple for \(d=0\)).
(Mis-)Calibration and standard metrics
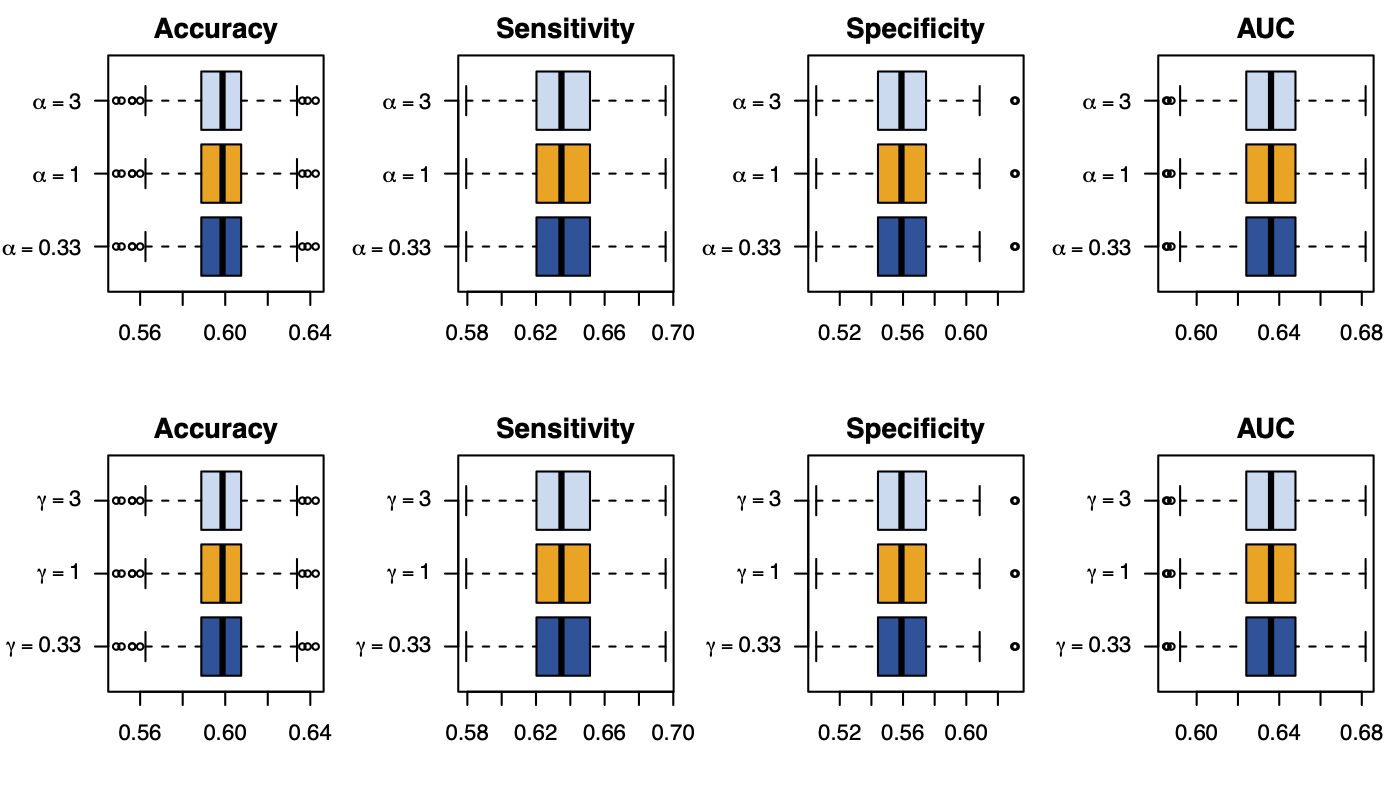
Figure 6: Standard Goodness of Fit Metrics on 200 Simulations for each Value of \(\alpha\) (top) or \(\gamma\) (bottom). The probability threshold is set to \(\tau=0.5\).
Scores Recalibration
Reference: metric computed using the uncalibrated scores \(\color{wongLightBlue}\hat{s}(\mathbf{x})\).
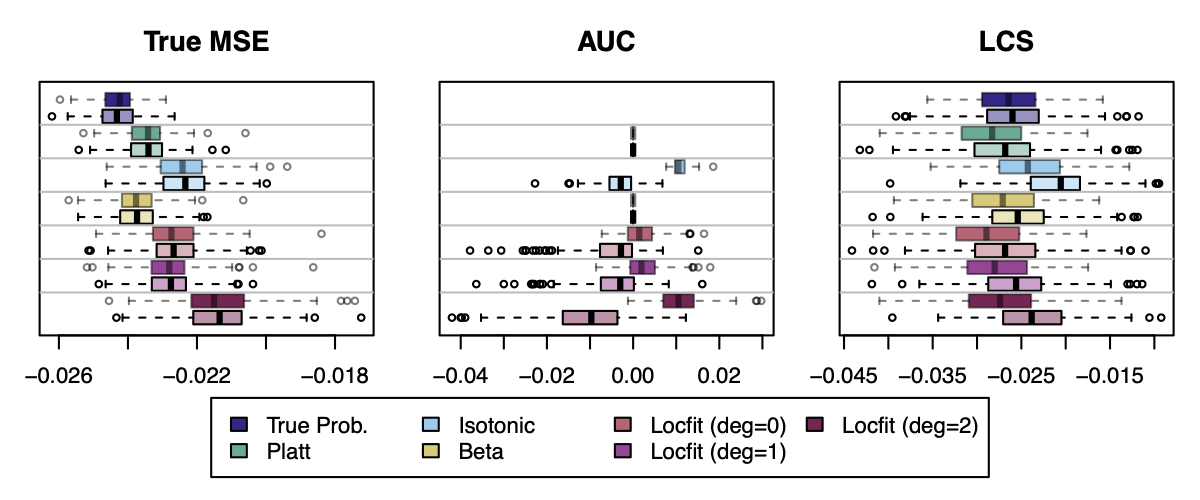
Figure 7: Metrics After Recalibration (for \(\gamma=3\)), on the Calibration (transparent colors) and on the Test Set (full colors).
Data Generating Process
We generate 200,000 obs: 100,000 in train, 50,000 in calibration, and 50,000 in test.
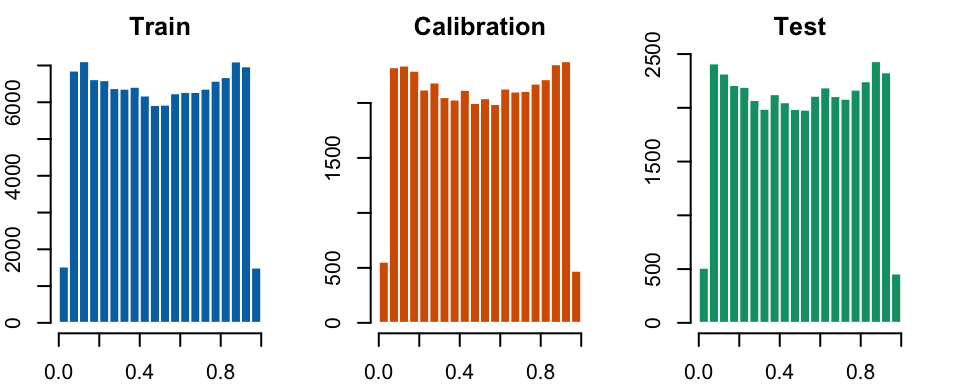
Figure 8: Distribution of the True Probabilities
Data Generating Process
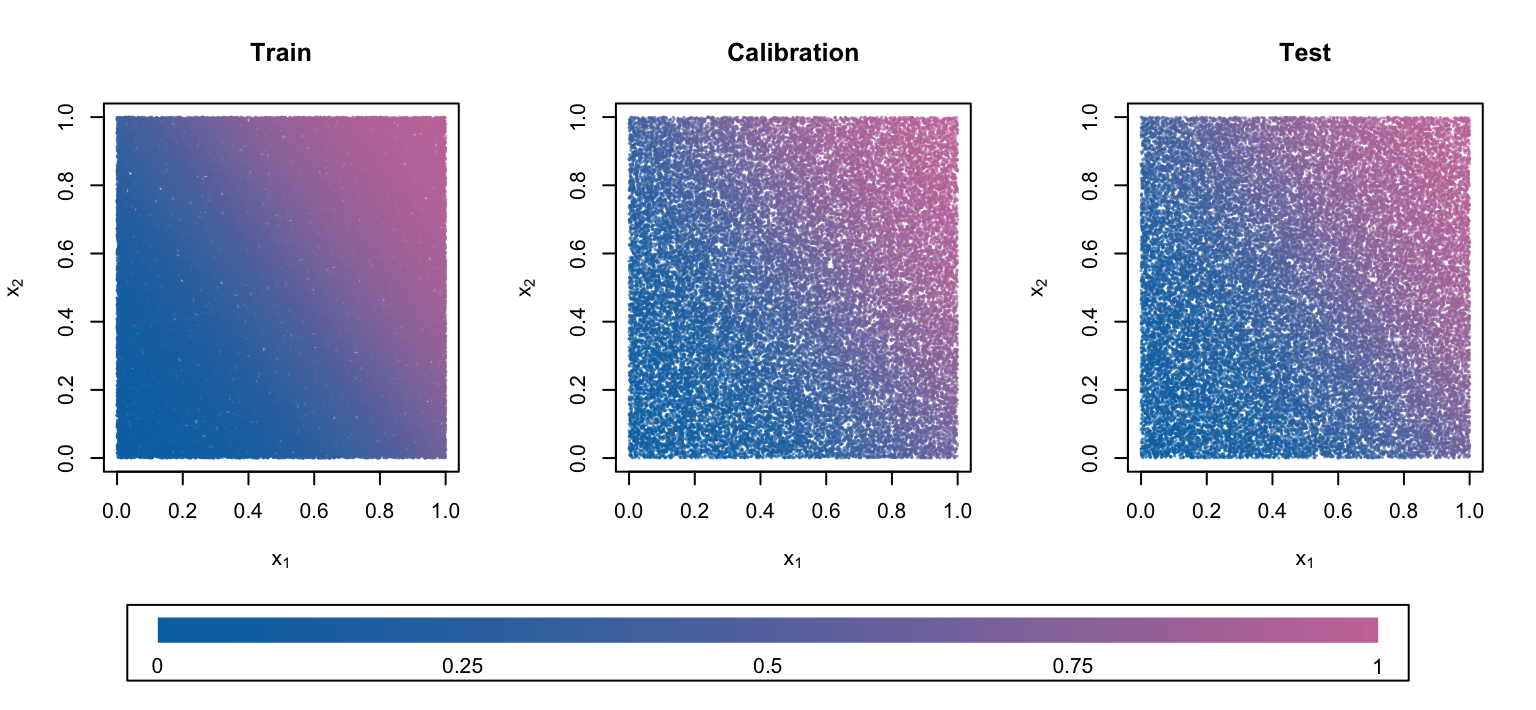
Figure 9: Drawn Probabilities \(p_i\)
Data Generating Process
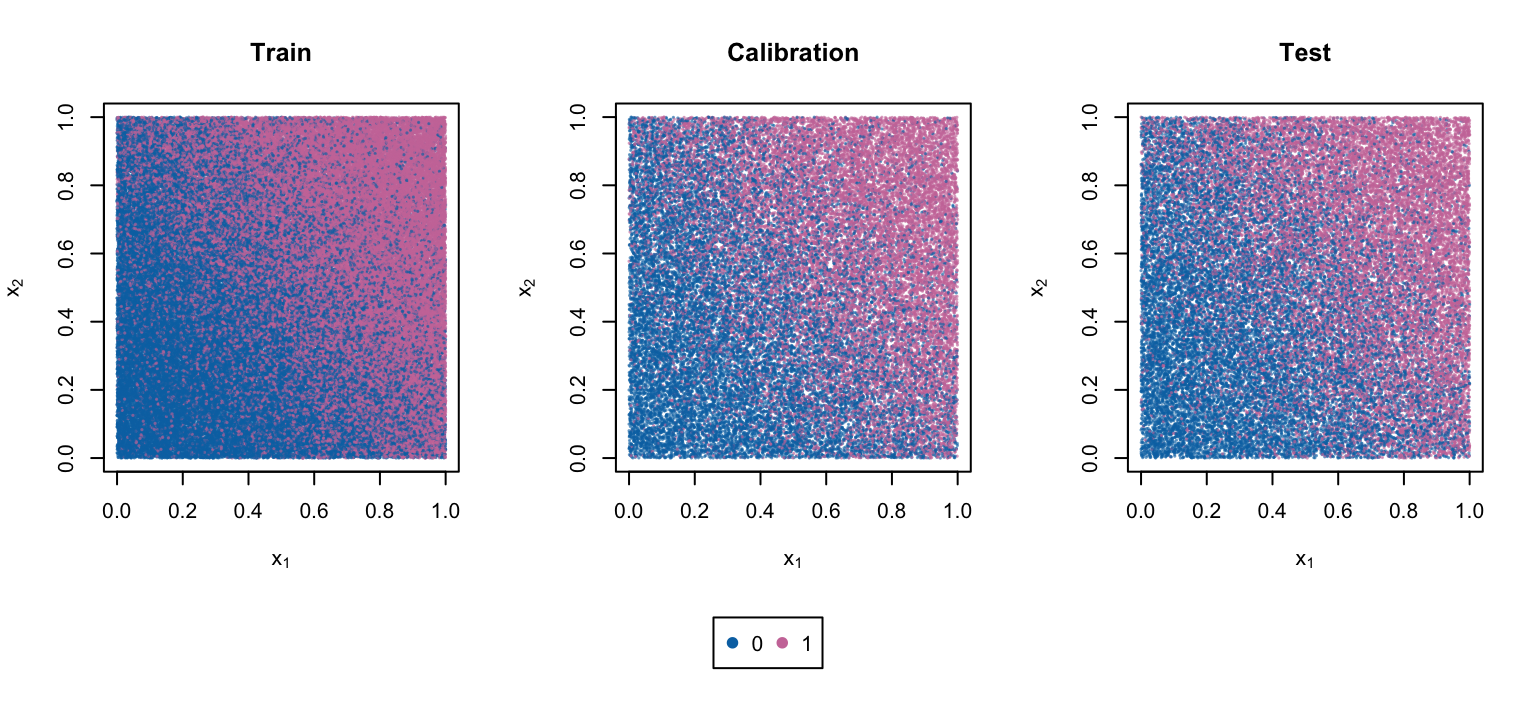
Figure 10: Observed Event \(d_i\)
Training a Regression Tree
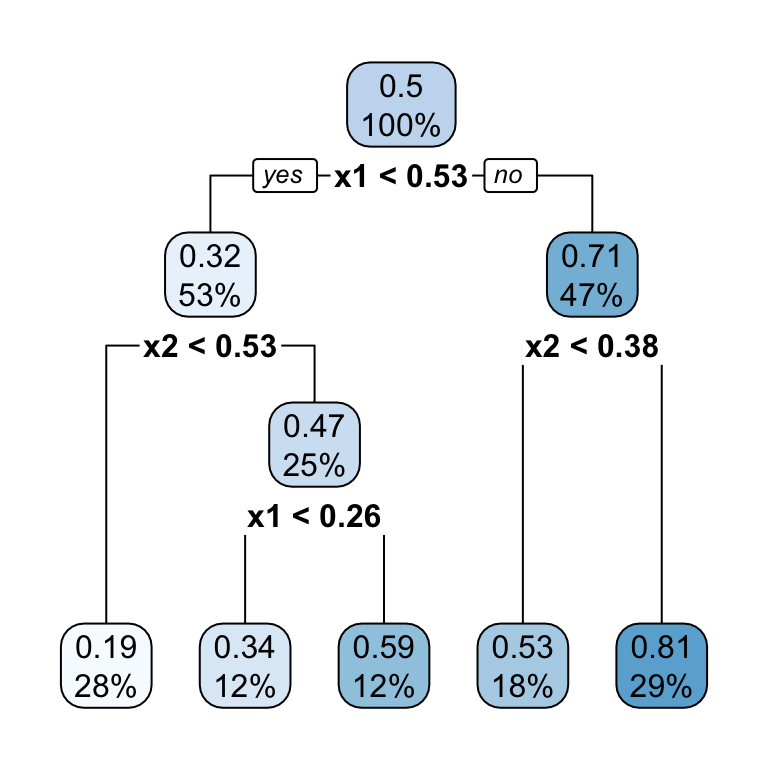
minbuckket = 12. In each node, the value on top is the average of \(d_i\) and the bottom value is the proportion of observations from the train sample.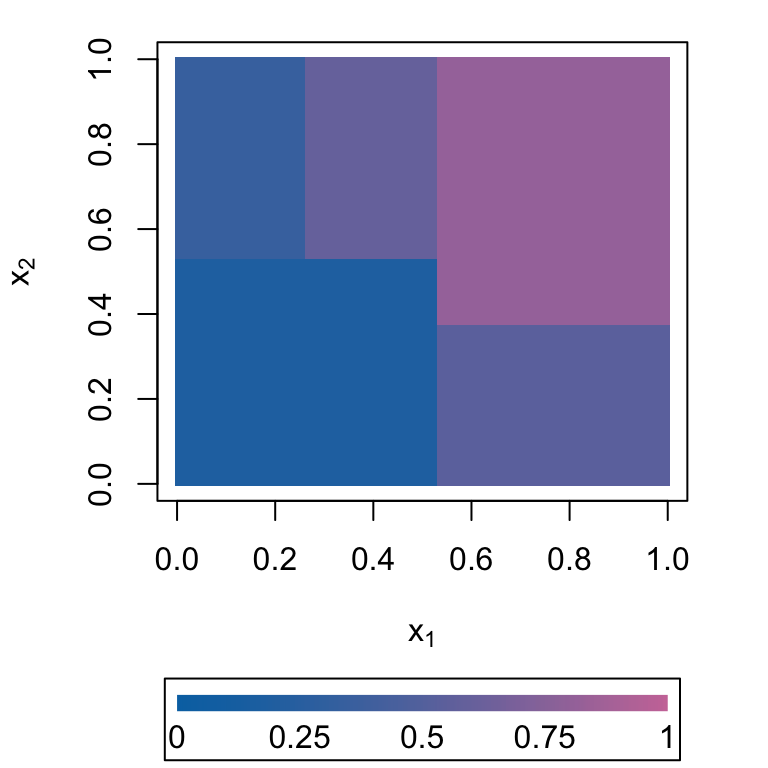
Calibration Curves
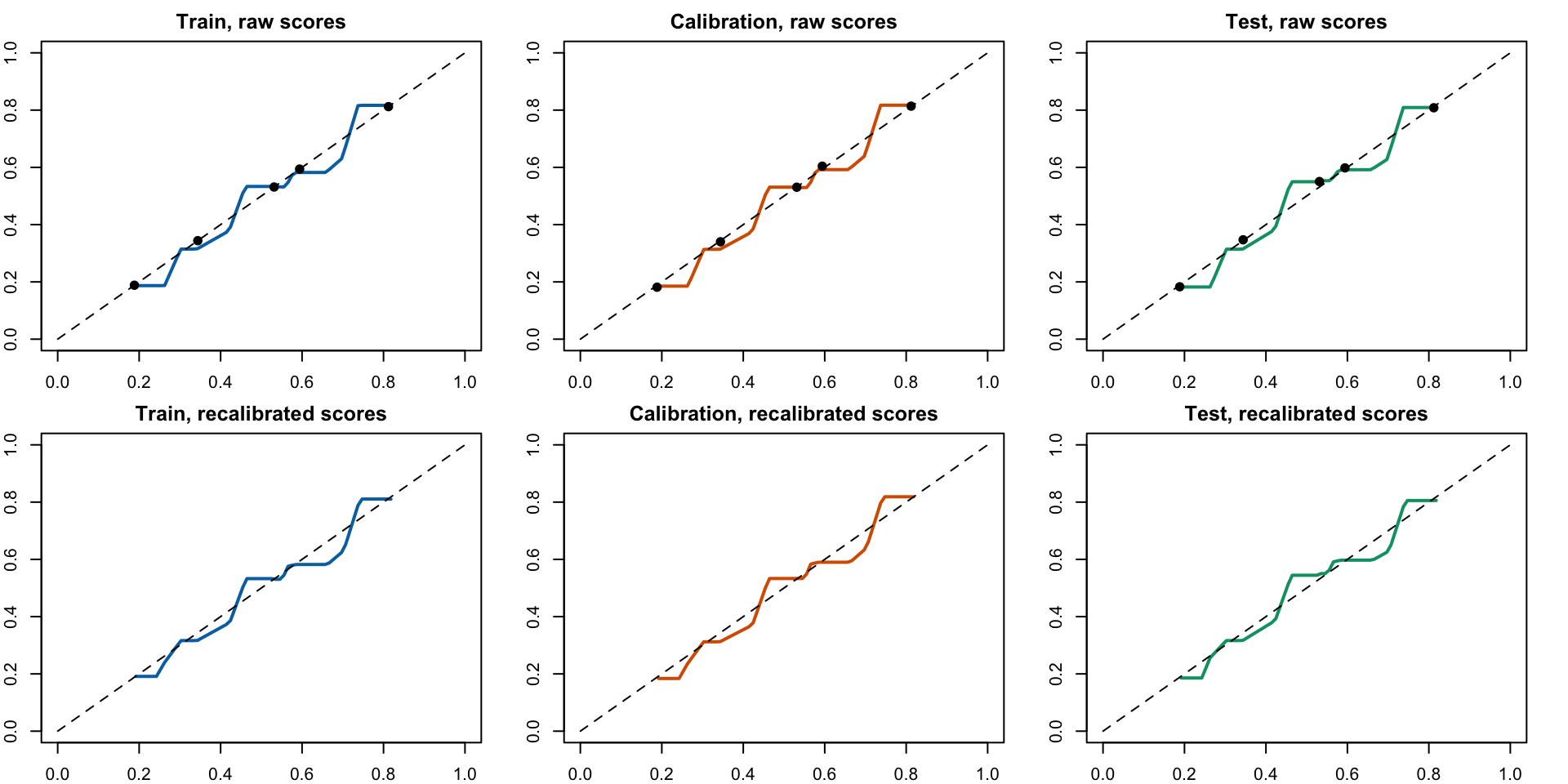
Figure 13: Calibration Curve with Uncalibrated Scores (top) and Recalibrated Scores (bottom)
Predicted Scores vs True Probabilities
Divergence, Performance and Calibration
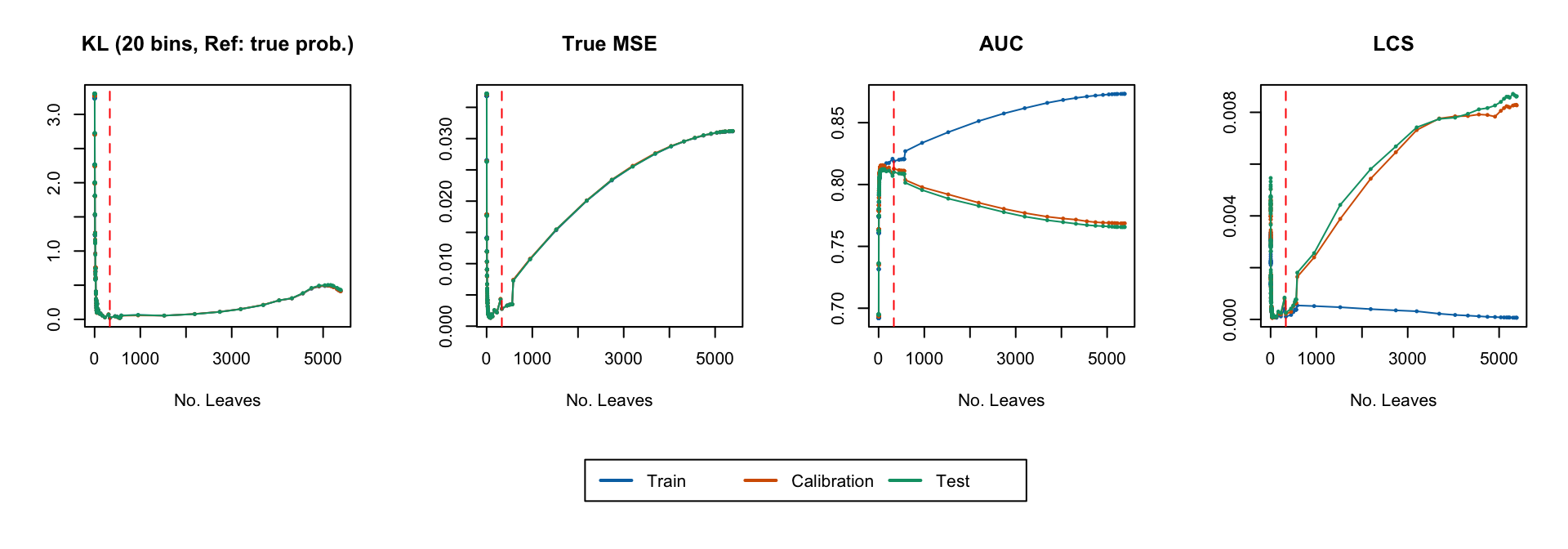
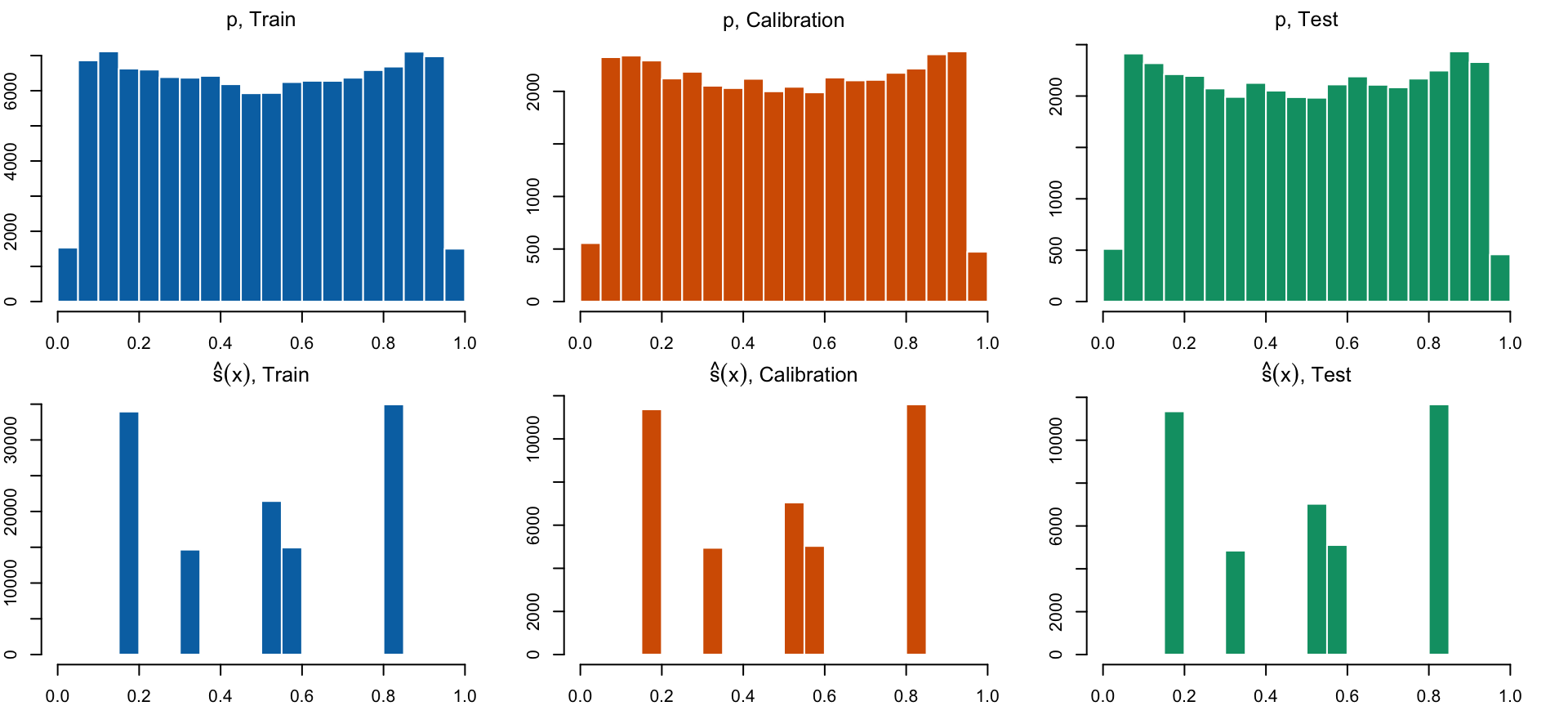
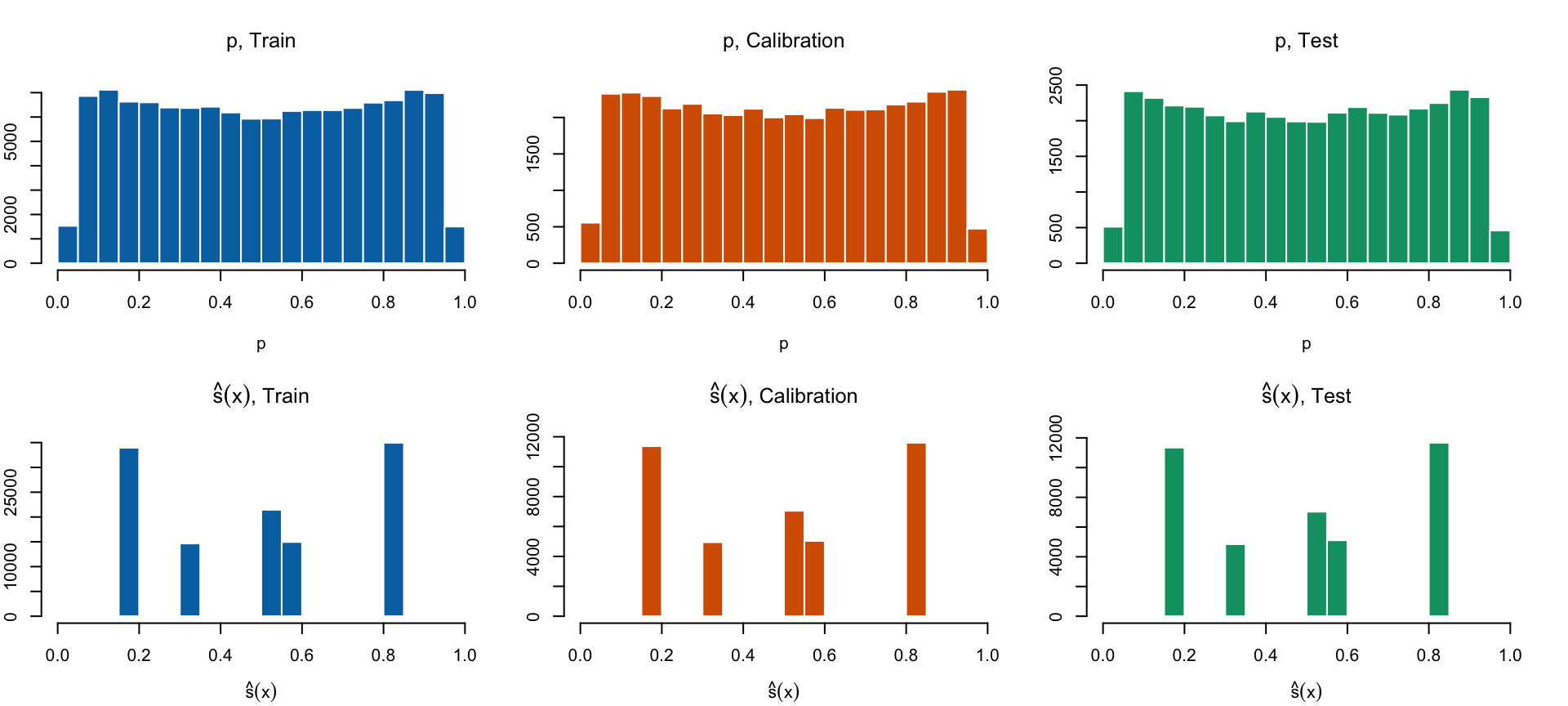
Distribution of Predicted Scores
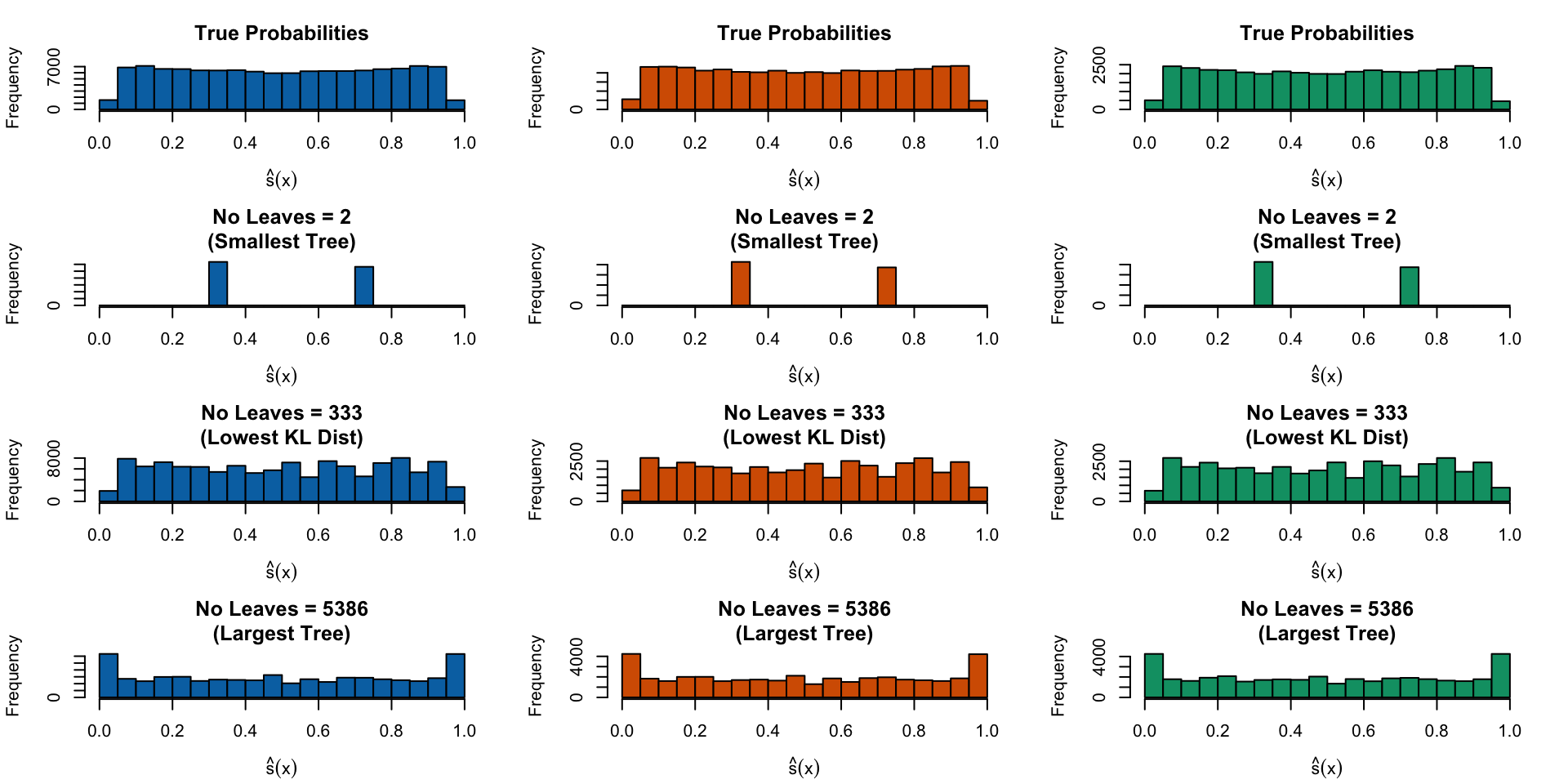
Figure 17: Distribution of true probabilities (top), estimated scores for the smallest tree (second row), for the tree with the smalled Kullback Leibler divergence (third row), and for the largest tree, when the minimal observations in terminal nodes is set to 1/1,000 of the number of observations in the train set.
References
Bai, Y., Mei, S., Wang, H., and Xiong, C. (2021). Don’t just blame over-parametrization for over-confidence: Theoretical analysis of calibration in binary classification. International Conference on Machine Learning : 566–576.
Breiman, L. (1984). Classification and regression trees. Wadsworth International Group.
Brier, G. W. (1950). Verification of forecasts expressed in terms of probability. Monthly Weather Review 78: 1–3.
Calster, B. V., David J. McLernon, and, Smeden, M. van, Wynants, L., and Steyerberg, E. W. (2019). Calibration: The achilles heel of predictive analytics. BMC Medicine 17.
Dawid, A. P. (1982). The well-calibrated bayesian. Journal of the American Statistical Association 77: 605–610.
Gutman, R., Karavani, E., and Shimoni, Y. (2022). Propensity score models are better when post-calibrated. https://arxiv.org/abs/2211.01221, last accessed
Hill, K., and White, J. (2020). Designed to deceive: Do these people look real to you? The New York Times 11.
Krüger, F., and Ziegel, J. F. (2020). Generic conditions for forecast dominance. Journal of Business & Economic Statistics 39: 972–983.
Kull, M., Filho, T. M. S., and Flach, P. (2017). Beyond sigmoids: How to obtain well-calibrated probabilities from binary classifiers with beta calibration. Electronic Journal of Statistics 11: 5052–5080.
Kull, M., Silva Filho, T. M., and Flach, P. (2017). Beyond sigmoids: How to obtain well-calibrated probabilities from binary classifiers with beta calibration. Electronic Journal of Statistics 11.
Kullback, S., and Leibler, R. A. (1951). On information and sufficiency. The Annals of Mathematical Statistics 22: 79–86.
Loader, C. (1999). Fitting with LOCFIT. In Local regression and likelihood. New York, NY: Springer New York, 45–58.
Machado, A. F., Hu, F., Ratz, P., Gallic, E., and Charpentier, A. (2024). Geospatial disparities: A case study on real estate prices in paris. https://arxiv.org/abs/2401.16197, last accessed
Pakdaman Naeini, M., Cooper, G., and Hauskrecht, M. (2015). Obtaining well calibrated probabilities using bayesian binning. Proceedings of the AAAI Conference on Artificial Intelligence 29: 2901–2907.
Platt, J. et al. (1999). Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Advances in Large Margin Classifiers 10: 61–74.
Schervish, M. J. (1989). A General Method for Comparing Probability Assessors. The Annals of Statistics 17: 1856–1879.
Wenger, J., Kjellström, H., and Triebel, R. (2020). Non-parametric calibration for classification. Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics (AISTATS). https://github.com/JonathanWenger/pycalib, last accessed
Wilks, D. S. (1990). On the combination of forecast probabilities for consecutive precipitation periods. Weather and Forecasting 5: 640–650.
Zadrozny, B., and Elkan, C. (2002, July). Transforming classifier scores into accurate multiclass probability estimates. Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. http://dx.doi.org/10.1145/775047.775151, last accessed